
Generative künstliche Intelligenzen (Generative KI) beherrschen spätestens seit ChatGPT die Schlagzeilen. Die Grundlage dieser neuen Generation KI sind Große Sprachmodelle (Large Language Models, LLMs). Inzwischen gibt es viele weitere wie Pi, Googles Bard, Metas Llama oder die deutschen Aleph Alpha. Richtig eingesetzt können sie verschiedene Bereiche, darunter Cybersicherheit, Behörden, Forschung, Finanzen oder die Kommunikation im Unternehmen oder mit Kunden revolutionieren. Juniper gehörte zu den ersten, die Netzwerkadministratoren mit ihrem intelligenten Chatbot Marvis das Leben erleichtert haben.
Neuere Sprachverarbeitungstools wie Pi oder der Chatbot von Groq können Texte mit bemerkenswerter Kohärenz und Genauigkeit generieren. Sie sind sogar in der Lage, das nächste Wort in einem Satz durch die Analyse riesiger Datenmengen vorherzusagen. Damit verändern LLMs die Art und Weise, wie wir arbeiten und kommunizieren grundsätzlich. Ihre potenziellen Anwendungsmöglichkeiten sind enorm. Die Auswirkungen können wir derzeit nur ansatzweise erahnen.
Kunden wollen Antworten. Sofort!
Um das Potenzial der Technologie voll ausschöpfen zu können, sind Interaktionen in Echtzeit erforderlich. Geschwindigkeit wird der große Wettbewerbsvorteil erfolgreicher Implementierungen. Die Herausforderung ist wie immer die Hardware. Herkömmliche Prozessoren inkl. GPUs und sämtlicher anderen verfügbaren xPUs sind für das Training großer Sprachmodelle konzipiert – nicht für die Erzeugung von Antworten (Schlußfolgern).
Groq ist ein Startup aus dem Silicon Valley und fokussiert sich genau auf dieses Problem: Inference Speed – also die Geschwindigkeit, Antworten generieren zu können. Dazu geht das Unternehmen auch ungewöhnliche Wege. CEO und Gründer Jonathan Ross ist Software-Entwickler. Und genau das hat er mit Groq getan: einen Compiler entwickelt und erst anschließend die Hardware speziell dafür kreiert. Die Language Processing Unit (LPU) von Groq ist zu 100% eine Eigenentwicklung und Grundlage des Portfolios.

Eine LPU Inference Engine für jeden Anwendungsfall
Die softwarebasierte Plattform kann KI-Anwendungen in Echtzeit und in großem Maßstab ausführen. Ziel ist es, ein Ökosystem für KI-Lösungen zu schaffen, bei dem die Software das der Entwicklung bestimmt und nicht die langsamen sowie teuren Hardware-Entwicklungszyklen. Die Architektur wurde von Grund auf für die Beschleunigung von KI-, ML- und HPC-Workloads konzipiert und ist optimiert für die Geschwindigkeit, Vorhersagbarkeit, Leistung und Genauigkeit von KI-Anwendungen und LLMs. Das Herzstück der Plattform ist der deterministische GroqChip-Prozessor. 16 Chip-to-Chip-Verbindungen und der integrierte Speicher reduzieren die Datenbewegungen für eine vorhersehbare Leistung bei niedriger Latenz. Die aktuelle Version (INT8, FP16 @900 MHz) erreicht bis zu 750 TOPs (Trillion Operations per Second) bzw. 188 TFLOPs.
Die Architektur unterscheidet sich grundlegend von aktuellen Chipdesigns.
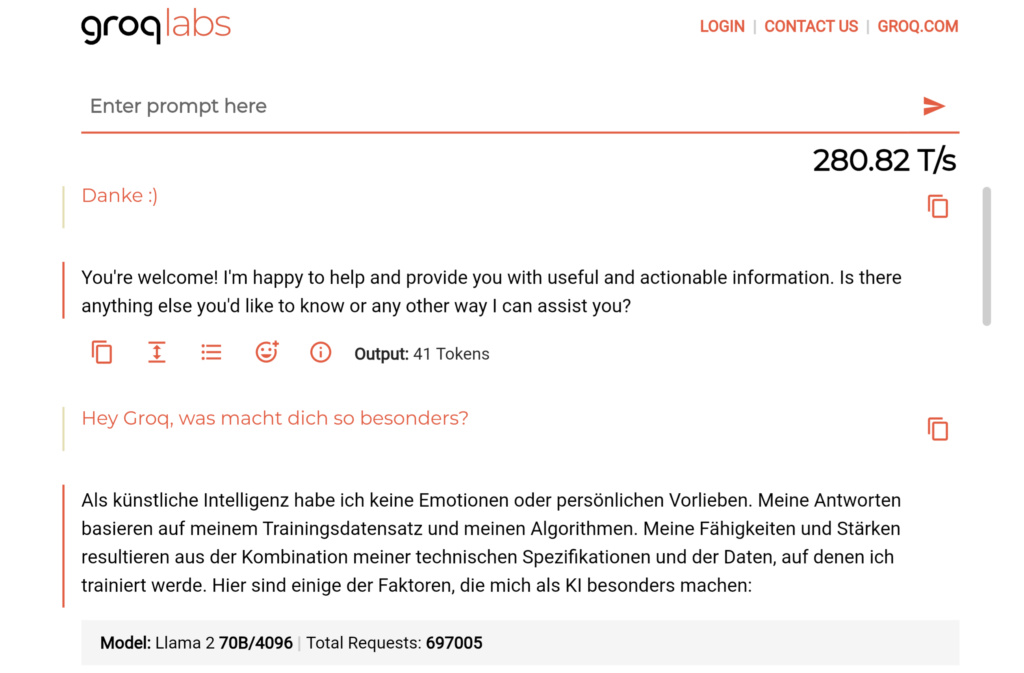
Der GroqChip erlaubt eine parallele Verarbeitung. Das bedeutet, dass er eine Vielzahl von Berechnungen gleichzeitig durchführen kann. Damit kann er schnell Antworten auch auf komplexe Fragen generieren. Der integrierte Switch erlaubt es, auf eine Vielzahl von Datenquellen zuzugreifen und so eine hohe Genauigkeit zu erreichen. Dafür stehen in der aktuellen Version 16 Ports zur Verfügung. Außerdem verfügt jeder Chip über 230 MB SRAM. 16 integrierte RealScaleTM Chip-to-Chip-Verbindungen mit einem integrierten PCIe Gen4 x16 Controller sorgen für bis zu 80 TB/s On-Die-Speicherbandbreite. Das Besondere an dem Chip ist, dass es ein Single Core ist.
Die Frage ist nicht, wieviele Cores auf einem Chip sind, sondern wieviele Chips in einem Core.
Jonathan Ross, Gründer und CEO von Groq
Mit 14 nm ist die Strukturgröße für den Zweck ausreichend. Zum Vergleich: Aktuell sind Strukturgrößen von 2 nm möglich – allerdings sind die Fertigungsprozesse alles andere als ausgereift und die Produktion auf wenige Musterstücke begrenzt.
Der Energieverbrauch liegt durchschnittlich bei 185W; maximal schaffte er es auf 300W.


Der CroqChip kann auch embedded verbaut werden, z. B. für Edge-Anwendungen. Der Regelfall dürfte aber der Einsatz im Rechenzentrum sein in Form einer PCIe-Karte für die Nachrüstung in bestehender Infrastruktur oder als GroqNode bzw. gleich als ganzes GroqRack.
Netzwerk neu gedacht
Auch Netzwerkstack und Instruction-Set sind Eigenentwicklungen von Groq. Die wichtigsten Schichten des Netzwerkstacks sind:
- Eingabe-Schicht: Hier werden Anfragen verarbeitet und in eine Form umgewandelt, die vom Netzwerk verstanden werden kann.
- Verarbeitungsschicht: In dieser Schicht werden Anfragen und Antworten analysiert, um die wichtigsten Informationen und Details zu extrahieren.
- Speicher-Schicht: In dieser Schicht werden die extrahierten Informationen und Details gespeichert, um sie später wieder zu verwenden.
- Compute-Schicht: In dieser Schicht werden aus den gespeicherten Informationen und Details die Antworten auf die Fragen generiert.
- Ausgabe-Schicht: Hier wird die generierte Antwort auf die Frage verarbeitet und wieder in eine verständliche Form für Menschen (oder andere Anwendungen) umgewandelt.
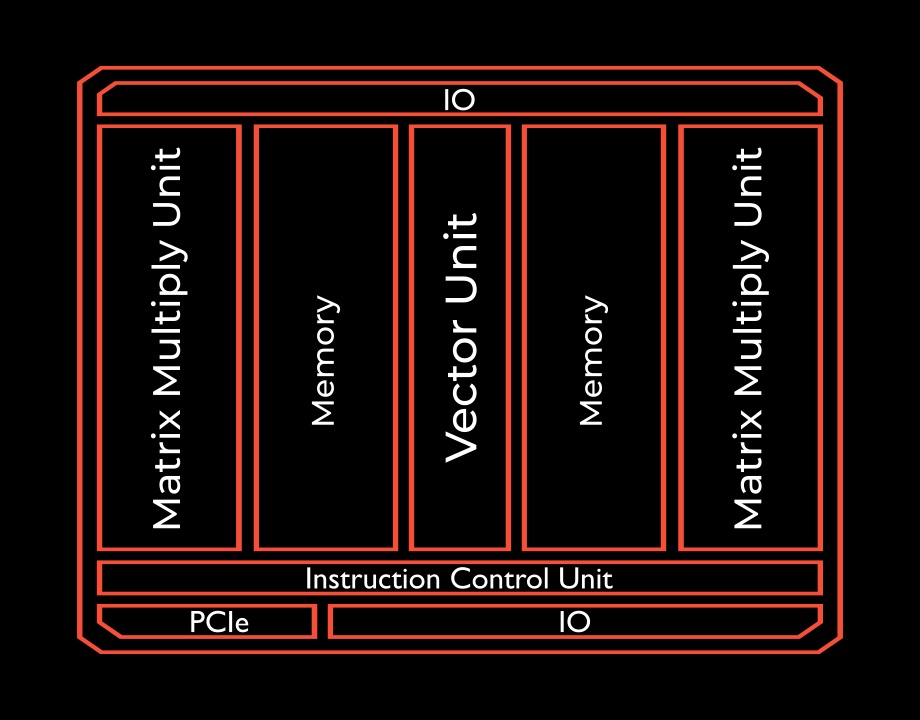
Das Ergebnis kann sich sehen lassen. Gegenüber der fein-granularen Kommunikation über die 16 direkt verbundenen Links auf jedem TSP (Tensor Streaming Processor) benötigt das A100-System eine etwa 3x höhere Netzwerkkanal-Bandbreite.
Da hilft es auch nicht, LLMs einfach mit mehr GPUs auszustatten. Das würde weder die bestehenden Latenz- noch die Skalierungsprobleme lösen.

Das Langzeitgedächtnis (Long Short-Term Memory, LSTM) ist eine Architektur rekurrenter neuronaler Netze (RNN). Viele Anwendungen dieser Modellklasse befassen sich mit Zeitreihendaten. Neben der Verarbeitung natürlicher Sprache sind Echtzeitsteuerungssysteme und Reinforcement Learning die bekanntesten Szenarien. Studien zu LSTM auf CPUs, GPUs, FPGAs und anderen Geräten zeigen, dass eine Beschleunigung in Hardware kaum möglich ist. Die mit dieser Modellklasse verbundenen so genannten Matrix-Vektor-Multiplikationen erfordern nur zwei arithmetische Operationen für jedes Byte der Eingabedaten. Das niedrige Verhältnis von Rechenoperationen zu Daten führt auf Architekturen, die nicht über die nötige Speicherbandbreite verfügen, zu Engpässen. Zusätzlich kann schleifenbedingte Abhängigkeit zwischen den LSTM-Zeitschritten einen Prozessor zum Stillstand bringen, bis die Ergebnisse der letzten Vektoroperationen für die nächste Runde der Matrix-Vektor-Multiplikation zur Verfügung stehen.
KI-Assistenz hängt ganz wesentlich davon ab, wie flüssig sie einen natürlichen Gesprächsrhythmus erzeugen kann. Mit der Inferenz-Engine von Groq lassen sich Leistung und Qualität sowohl bei Open-Source- als auch bei kundeneigenen Modellen steigern. Groq hat mit Llama-2 70B, dem LLM von Meta AI, einen Leistungsrekord von mehr als 300 Token pro Sekunde und Benutzer aufgestellt und hält derzeit den grundlegenden Leistungsrekord für Geschwindigkeit und Genauigkeit. Und das obwohl (oder trotzdem) der GroqChip ein einfacheres Design und Layout als Grafikprozessoren hat. Das macht ihn kostengünstiger und damit attraktiv für Kunden, die LLMs in eigene Tools und Dienste integrieren wollen.
Schnell ist gut. Perfekt ist besser.
Bei einem LLM ist nicht nur die Geschwindigkeit entscheidend. Es gibt mehrere Möglichkeiten, die Qualität einer künstlichen Intelligenz zu testen: man kann beobachten, wie das Modell in standardisierten Tests abschneidet (z. B. in der Fahrschule oder einer staatlichen Anwaltsprüfung) oder man läßt die Antworten von Menschen bewerten. Entscheidend für bessere Ergebnisse sind Modellgröße (Anzahl der Parameter) und Kontextlänge (maximale Größe der kombinierten Eingabe und Ausgabe).
Ein Modell mit 70B Parametern liefert bessere Antworten als ein Modell mit 7B Parametern. Eine größere Sequenzlänge führt zu relevanteren Antworten. Je mehr Informationen zur Verfügung stehen und in Kontext gesetzt werden können, desto genauer ist das Ergebnis. Größere Modelle und Sequenzlängen haben jedoch andere Ansprüche an die Rechenleistung. Der GroqChip wurde genau auf diese Anforderungen hin konzipiert.
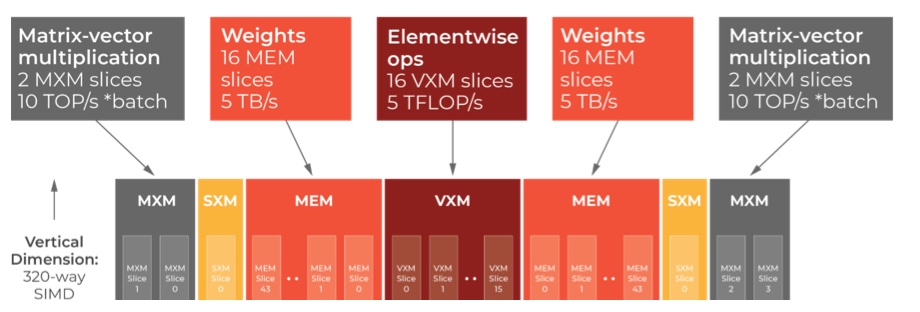
Matrix-Vektor-Multiplikationen benötigen eine hohe Speicherbandbreite, können latenzbedingt aber nur punktuelle Operationen verarbeiten. Der GroqChip löst dieses Problem mit einem Verhältnis von Rechenleistung zu Speicher sowie der Funktion zur Verkettung von Operationen. Matrix-Vektor-Multiplikationen und punktförmige Operationen werden jeweils direkt entweder auf dem Matrix-Ausführungsmodul (MXM) oder dem Vektor-Ausführungsmodul (VXM) abgebildet.
Wer braucht denn so was?!
Ob ein Unternehmen oder bestimmte Abteilungen tatsächlich von KI profitieren, hängt von unterschiedlichen Faktoren ab. Bei der Entwicklung einer KI-Strategie sollten sich Organisationen u. a. die folgenden Fragen stellen:

- Welche transformativen KI-Möglichkeiten gibt es generell für meine Branche und speziell meine Organisation?
- In welchen Bereichen kann KI eingesetzt werden, um z. B. Prozesse produktiver und Mitarbeitende kreativer zu machen?
- Gibt es bereits bestehende LLMs für meinen Anwendungsfall (Purpose Build LLM)? Wie gut sind die verfügbaren Inferenzlösungen für meine Anforderungen geeignet?
- Wie können diese LLMs zur Veränderung der Organisation beitragen? Wie kann Prompt Engineering Produkte, Dienstleistungen oder Abläufe verbessern oder verändern?
- Wer profitiert von Echtzeitinteraktionen mit einer KI und wie? Was kann KI in ganz speziellen Fällen liefern.
- Welche Anforderungen stellt KI an die Infrastruktur?
- Wie groß muss das Modell und die Sequenz sein, damit diese Lösungen erfolgreich sind? Was sind meine Qualitätsparameter?
- Kann die bestehende Infrastruktur die geforderte Geschwindigkeit in dem erforderlichen Umfang (systemweite Abfragen pro Minute) liefern und beibehalten? Wie skaliert die Infrastruktur mit steigenden Bedürfnissen?
- Welche Infrastrukturplattform kann die geforderte Latenzzeit und Geschwindigkeit bei der gewünschten Modellgröße und Sequenzlänge unterstützen?
- Welche dieser Plattformen können zusätzliche qualitätssteigernde Algorithmen wie Balkensuche und Selbstreflexion unterstützen und gleichzeitig die minimale Latenz und Geschwindigkeit erreichen?
- Wie hoch sind die Rechenkosten ($/ Token) für die in Frage kommenden Plattformen?
Seit Dezember 2023 ist der GroqChat öffentlich verfügbar. GroqChat ist eine Alphaversion des grundlegenden LLMs der AI von Meta, welches auf der Groq LPU Inference Engine läuft. Early Access zur Groq-API ist ab Januar 2024 möglich. Zugelassene Nutzer können darüber mit Llama-2 70B, Mistral und Falcon experimentieren, die ebenfalls alle auf der LPU Inference Engine von Groq laufen.
Wir trafen Jonathan Ross, Gründer und CEO von Groq im Januar 2024 während der IT Press Tour in Palo Alto.

