
Moderne Rechenzentren benötigen eine Speicherlösung für eine Vielzahl von Workloads. Das Training von KI-Modellen ist besonders anspruchsvoll. Aufbau und Training hochleistungsfähiger KI wie großen Sprachmodellen (LLM) – z. B. Facebooks LLAMA 3 – erfordern eine enorme, konstante Leistung. Herkömmliche NAS-Architekturen werden diesen Anforderungen (einer Mischung aus dem Streaming großer Dateien, leseintensiven Anwendungen und zufälligen Lese- und Schreiboperationen) nicht gerecht.

GenAI-Trainingsaufgaben werden im Laufe der Zeit multimodaler und benötigen immer größere Mengen an Bild-, Video- und Textdaten. Damit steigt der Bedarf an Datenspeicherung und die Notwendigkeit, all diese Daten in einem leistungsfähigen und gleichzeitig energieeffizienten System zu speichern, rapide an.
Große Tech-Unternehmen entwickeln dafür nicht selten ihre eigenen hochoptimierten Racks und Server. Die Systeme sind äußerst energieeffizient, wartungsfreundlich und oft sogar kabellos.
Anatomie eines Hyperscalers

Für die täglich bis zu mehreren Billionen KI-Modellausführungen hat Meta eine hochmoderne und flexible Infrastruktur entwickelt. Die Infrastruktur umfasst zwei Versionen eines GPU-Clusters mit derzeit insgesamt 24.576 NVIDIA Tensor Core H100 Grafikprozessoren; bis Ende 2024 sollen es 350.000 werden. Ein Cluster nutzt RDMA (Remote Direct Memory Access) und konvergiertes Ethernet (RoCE) und basiert auf Arista- und Minipack2-OCP-Rack-Switches. Der zweite Cluster verfügt über eine NVIDIA Quantum2 InfiniBand Fabric. Beide Cluster basieren auf Metas selbst entwickelter, offener GPU-Hardwareplattform Grand Teton. Stromversorgungs-, Steuerungs-, Rechen- und Fabric-Schnittstellen sind in einem einzigen Gehäuse integriert. Meta bietet eine interaktive 3D-Erkundung seiner Hardware (z. B. mit MetaQuest) an.
Die Speicherlösungen in Metas GenAI Clustern basiert auf der YV3 Sierra Point Serverplattform und aktuellen E1.S SSD mit hoher Kapazität. Die OCP-Server skalieren flexibel. Konzeption und Anzahl der Server pro Rack helfen, sowohl den physischen als auch ökologischen Fußabdruck zu reduzieren und sind gleichzeitig fehlertolerant gegenüber täglichen Wartungsarbeiten an der Infrastruktur. Design und Architektur sind optimiert für eine ausgewogene Balance zwischen Durchsatzkapazität und Energieeffizienz.

Hyperscaler mit Hyperscale NAS
Meta deckt einen Großteil der Anforderungen mit seiner selbst entwickelten und für Flash-Medien optimierten Version der verteilten Speicherlösung Tectonic und der ebenfalls selbst entwickelten FUSE-API (Linux Filesystem in Userspace) ab. Der flexible und durchsatzstarke Speicher im Exabyte-Bereich ermöglicht es Tausenden von GPUs, Checkpoints synchron zu speichern und zu laden. Trainingszeiten von Modellen mit zig Milliarden Parametern können bis auf ein Drittel reduziert werden.
Codeänderungen sind in den Clustern sofort für alle Knoten innerhalb der Umgebung zugänglich. Für sein AI Research SuperCluster hat Meta zusätzlich gemeinsam mit Hammerspace ein paralleles Netzwerk-Dateisystem (NFS) entwickelt. Damit sollen vor allem die Anforderungen der Entwickler an den KI-Cluster erfüllt und den Ingenieuren ein interaktives Debugging für Jobs mit Tausenden von GPUs ermöglicht werden. Die Kombination aus Metas verteilter Speicherlösung Tectonic und dem Hyperscale-NAS von Hammerspace ermöglicht eine schnelle Iterationsgeschwindigkeit.
Speichern wie ein Hyperscaler
Organisationen wie Meta, Google und Amazon haben ihre Architektur hyper-skaliert, d. h. für Hypereffizienz und High-Performance-Computing optimiert. So wurde z. B. Amazon Web Services (AWS) S3 für groß angelegte, effiziente Speicherung entwickelt. Die Hypercale-NAS-Plattform von Hammerspace macht fortschrittliche Methoden von Technologieunternehmen wie AWS oder Meta verfügbar für Unternehmen jeder Größe und ermöglicht damit u. a. das individuelle Training generativer KI-Modelle.
Unternehmen, die KI-Initiativen verfolgen, stehen mit ihrer bestehenden IT-Infrastruktur vor der Herausforderung, einen Kompromiss zwischen Geschwindigkeit, Skalierbarkeit, Sicherheit und Einfachheit zu finden. Diese Unternehmen benötigen die Leistung und die kosteneffiziente Skalierung von parallelen HPC-Dateisystemen und müssen die Anforderungen des Unternehmens an Benutzerfreundlichkeit und Datensicherheit erfüllen. Hyperscale NAS ist eine grundlegend andere NAS-Architektur, die es Unternehmen ermöglicht, das Beste der HPC-Technologie zu nutzen, ohne Kompromisse bei den Unternehmensstandards einzugehen.
David Flynn, Gründer und CEO von Hammerspace
Mit seinem Hyperscale NAS hilft Hammerspace bei der Beseitigung von Speicherengpässen und stellt GPU-Computing-Farmen die erforderliche Architektur in den Bereichen KI, maschinelles Lernen und Deep Learning (KI/ML/DL) zur Verfügung. Dazu werden die Metadaten vorhandener Dateisysteme übernommen. Anwender und Anwendungen greifen mit Hilfe von Standardprotokollen über bestehende Ethernet- oder InfiniBand-Netzwerke sowie die vorhandene Speicherinfrastruktur auf die Daten zu. Es werden weder Agenten noch proprietäre Client-Software benötigt.

Die Hyperscale NAS-Architektur von Hammerspace kann für das Training von KI-Modellen in Umgebungen mit bis zu 1.000 Speicherknoten und 30.000 Grafikprozessoren bei einem Durchsatz von bis zu 80 Terabit/s über Standard-Ethernet und TCP/IP eingesetzt werden.
Hoher Durchsatz, niedrige Latenz
Das Hammerspace-Dateisystem ist für NVIDIA GPUDirect Storage zertifiziert. Mit GPUDirect Storage kann die Abarbeitung von Datenpipelines für KI-Workloads beschleunigt und NVIDIA GPUs effizienter ausgelastet werden. Durch den Einsatz globaler Dateimanagementsysteme lässt sich jedes bestehende Speichersystem als GPUDirect Storage präsentieren.
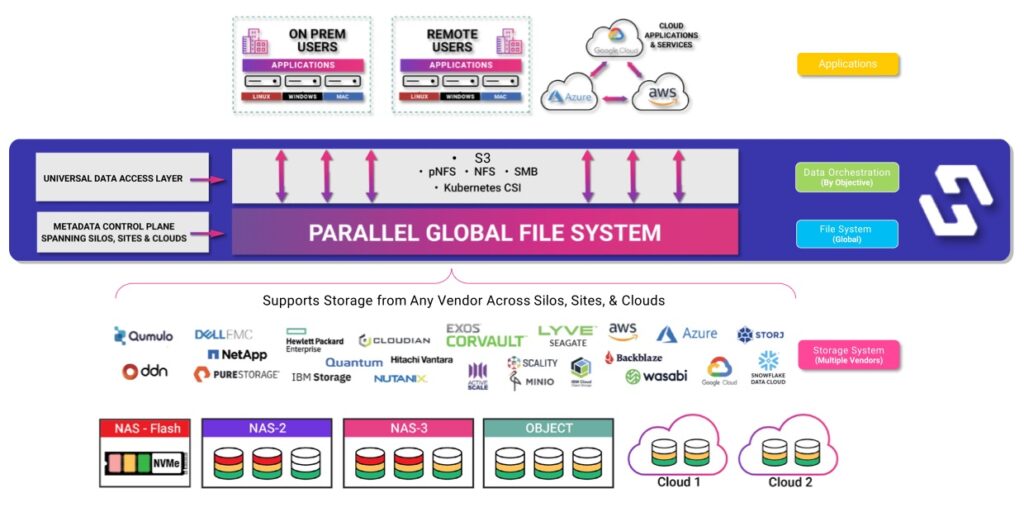
Daten können bei Bedarf dorthin zu verschoben werden, wo sie für die Verarbeitung in Analysen und KI-Modellen benötigt werden. Dabei ist es egal, ob die Daten lokal, in public Clouds oder externen Analyseplattformen wie Snowflake und Databricks genutzt werden sollen.
Modern und compliant
Unternehmen müssen künftig KI zu nutzen, um ihre Umsätze zu steigern und die betriebliche Effizienz zu verbessern. KI-Modelle müssen mit großen Datenmengen trainiert werden, um möglichst genau zu sein. Je mehr Daten ihnen zur Verfügung stehen, desto genauer werden die Ergebnisse von Anfang an sein. KI-Modelle, die nur Daten aus einem einzigen Speichersilo nutzen können, haben einen großen Nachteil gegenüber solchen, die auf eine Vielzahl von über mehrere Speicherplattformen und Standorte verteilten Datensätzen zugreifen können. Eine der größten Herausforderungen für KI-Architekten ist allerdings, verteilte unstrukturierte Datensätze gesetzeskonform in ihre KI-Strategien einzubinden. Hammerspace hilft den Unternehmen, auch strenge Anforderungen an Compliance, Sicherheit und Data Governance zu erfüllen.
Standardiserte Datenschnittstellen und -Datendienste spielen eine entscheidende Rolle bei der Einhaltung gesetzlicher Vorschriften. Hammerspace nutzt den Industriestandard NFS als Schnittstelle zu den Daten. Die Unterstützung offener Standards wie sie die Open Compute Platform nutzt und Partnerschaften mit regionalen Anbietern wie PoINT Software & Systeme oder Grau Data helfen Unternehmen bei Aufbau und Betrieb einer eigenen gesetzeskonformen, hochleistungsfähigen KI-Infrastruktur. Offene KI-Modelle wie Metas Llama können auch auf eigenen LLM-Servern betrieben werden.

In einem Blogpost stellt die AI Infrastructure Alliance nützliche Werkzeuge und Überlegungen zum Aufbau einer eigenen KI-Infrastruktur vor. Fertige KI-Server für den on-prem-Betrieb inkl. vortrainierter Modelle gibt es bei Samba Nova. Für kleinere Unternehmen oder einzelne Abteilungen gibt es Infrastructure as a Service von deutschen Anbietern wie Genesis Cloud. Infrastruktur auf Basis des Open Compute Projects bietet ScaleUp Technologies, ebenfalls aus Deutschland. Die Open Telekom Cloud bietet einen Fullstack KI as a Service auf ihrer Plattform und kündigt die Verfügbarkeit vortrainierter Modelle an.
Wir trafen Hammerspace-Gründer und CEO David Flynn im Januar 2024 im Rahmen der IT Press Tour im Silicon Valley.

