Die zunehmende Verbreitung von KI in allen Branchen verändert die Anforderungen an die Datenverarbeitung und damit auch an den Storage. Künstliche Intelligenz ist aktuell noch stark von der Leistung zusätzlicher GPUs angewiesen. Engpässe in Netzwerk und Storage wirken sich auf die Trainingszeiten und die Verfügbarkeit von Ergebnissen aus. Effiziente Datenpipelines können helfen, Entscheidungs- und Markteinführungszeiten zu verkürzen. Vor allem aber können teure Ressourcen wie GPUs effizienter eingesetzt und besser genutzt werden. Moderne Storageplattformen wie die von Weka sorgen für weniger Stillstand in der GPU-Farm.

Grafikprozessoren sind teuer. Wer in eine GPU investiert wünscht sich eine hohe Auslastung für seine Anschaffung. Storage-Backends können einen wichtigen Beitrag leisten, dass sich GPUs nicht langweilen während sie auf Daten warten.
Die KI-Datenpipeline
KI/ML-Infrastruktur besteht aus verschiedenen Schlüsselelemente, z. B. für das Training und Schlussfolgerungen (Inferences):
- Allgemeine Rechenressourcen wie Hauptprozessort (CPU) oder Arbeitsspeicher (RAM) für das Betriebssystem, Unterstützung der KI/DL-Frameworks und I/O-Operationen zwischen allen Systemen
- Beschleuniger für spezielle Rechenoperationen wie Fließkomma-Berechnungen (z. B. GPU oder spezielle AI-Chips)
- Speicher für Trainingsdaten, Inferenzdaten und Modelle
- Netzwerk zur Verbindung der unterschiedlichen Elemente
Für das Training von KI werden viele Daten benötigt, die oft in verschiedenen Speichern an unterschiedlichen Orten liegen. Die Schlussfolgerungen einer KI sind das Ergebnis vieler verteilter Rechen- und GPU-Operationen. Jeder einzelne Schritt einer KI-Berechnung hat unterschiedliche Anforderungen und nutzt eigene Protokolle. Der Nachrichtenaustausch bei parallelen Berechnungen auf verteilten Computersystemen basiertauf dem Message Passing Interface (MPI). GPUs nutzen untereinander zur Kommunikation das von NVIDIA entwickelte NVlink. Storagesysteme kommunizieren über iSCSI, Fibrechannel oder NVMe. Daten kommen via SMB, NFS oder S3 zu den Anwendungen.

Faktoren wie die Anzahl der gleichzeitig von einem Grafikprozessor ausgewerteten Informationen (Stapelgröße), Modellgröße oder Genauigkeit der Modellgewichtung (z. B. FP32/16/8/4) bestimmen, wie stark ein Grafikprozessor während eines Jobs ausgelastet ist. Durch Modelloptimierung können GPUs effizienter ausgelastet werden. Es gibt jedoch eine Reihe weiterer Faktoren, die sich auf die Auslastung (oder eben Nicht-Auslastung) auswirken.
Das schwächste Glied der Kette
Jede Ebene erbt Einschränkungen von den niedrigeren Ebenen des KI-Stacks. Mangelnde Leistung der Datenstruktur oder ein Problem mit dem Betriebssystem bzw. dem Netzwerk wirken sich kaskadierend aus.
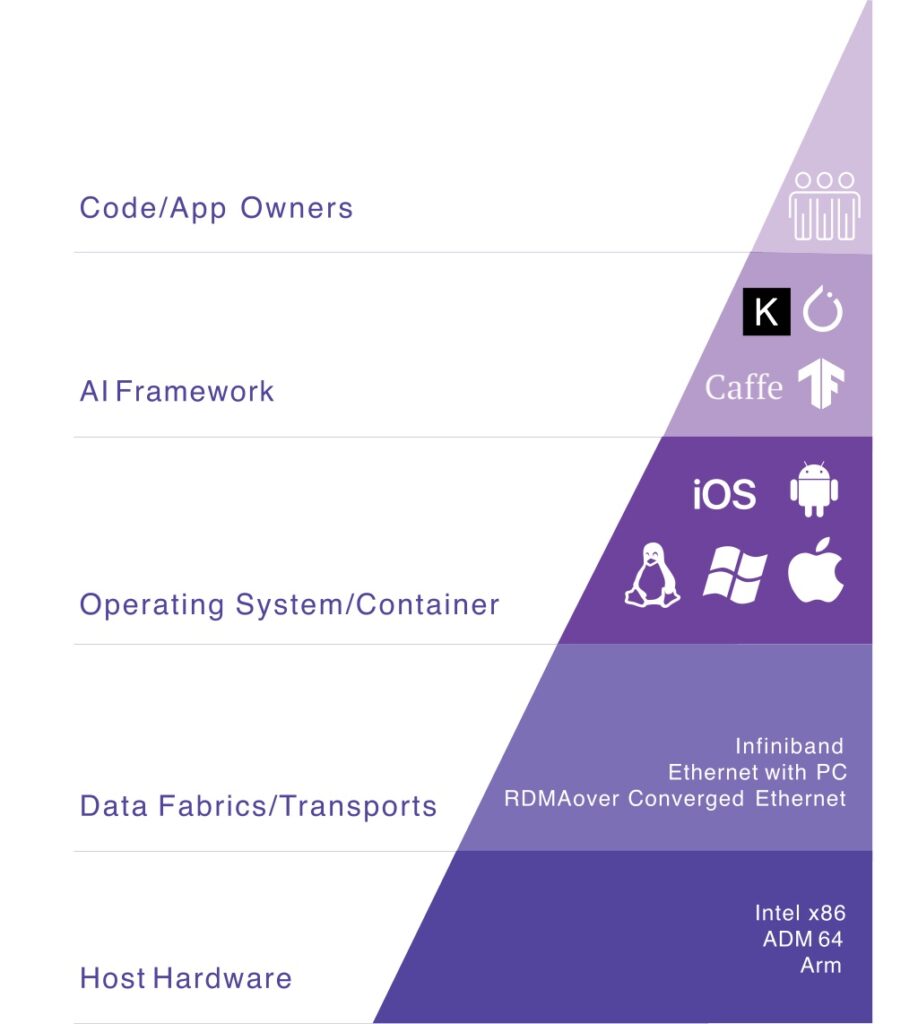
Leistungsprobleme können auf allen Infrastrukturebenen auftreten. Leidtragende sind am Ende die Projekteigentümer, Entscheider oder Forschenden, die lange auf Ergebnisse warten müssen.
Eine verbreitete Ursache für Leistungseinbußen sind z. B. Metadaten-Lookups. Die Suche nach Informationen über eine bestimmte Dateisystemeigenschaft, wie z. B. den Speicherort in einem Verzeichnis oder die Dateigröße, kann eine große Herausforderung für bestehende Infrastrukturen darstellen. Herkömmliche NAS/SAN-Systeme arbeiten oft noch hochverfügbaren Controller-Paaren. Die Metadaten sind auf die Domäne dieses Controler-Paars beschränkt. Für Daten, die sich über mehrere Systeme verteilen, müssen die Metadaten zwischengespeichert (cached) werden. Je größer das Dateisystem ist, desto mehr Speicherplatz wird für das Caching der Metadaten benötigt. Auch wenn die HA-Paare einen Scale-Out-Cluster bilden, ist die gemeinsame Nutzung von Metadaten innerhalb des Clusters in der Regel begrenzt, selbst wenn das Dateisystem im gesamten Cluster skaliert. Dateisysteme mit dedizierten Metadaten-Servern sind komplex und wirken sich ebenfalls auf die Verfügbarkeit der Daten für die GPU aus.
Moderne Architekturen verbinden Hosts, Storage und Clients über ein möglichst verlustfreies Netzwerk. Dabei kommen neue Protokolle wie NVlink, GPUdirect, alte Bekannte wie RDMA over convergent Ethernet (RoCE) und Infiniband oder innovative Erweiterungen des PCIe-Protokolls wie NVMe und vielleicht bald auch CXL zur Anwendung. Globale Namespaces vereinfachen die Verwaltung speicher- und standortübergreifend. Einheitliche Storagesysteme (Unified Storage) vereinen verschiedene Arten von Daten (Block, File, Object) und Zugriffsprotokollen (z. B. NFS/CIFS, SMB, S3) zu einem einzigen Speicherpool.
Storage-Plattformen neuer Anbieter wie Weka, Hammerspace oder VAST Data sind speziell für die Anforderungen aktueller und künftiger Workloads konzipiert und entwickelt.

Neueste Entwicklung des frischgebackenen Einhorns ist der WEKApod – zertifiziert für NVIDIA-DGX-SuperPOD-Systeme und integriert im NVIDIA Base Command Manager.
Wer Weka einmal ausprobieren möchte: Das Unternehmen bietet einen kostenlosen Test der Plattform auf seiner Website an.
Wir trafen Vertreter von Weka, u. a. CTO Shimon Ben-David (zweiter von links) im März 2024 im Rahmen der IT Press Tour.

