Machine Learning (ML) und künstliche Intelligenz stellen neue Anforderungen an Storage. Klassisches Tiering gehört nicht dazu. Auch Vorhersagen, welche Daten wahrscheinlich als nächstes abgerufen werden, helfen nicht bei der Verbesserung der Performance. Vorbei sind auch die Zeiten, als im HPC-Umfeld galt „Mehr ist mehr“. Moderne AI- und HPC-Workloads zwingen Storage-Hersteller zum Umdenken. Einer, der Storage komplett neu gedacht hat, ist die 2016 gegründete VAST.
Wie anders VAST ist, zeigt ein Blick auf die Liste der VAST-Gründer: Renen Hallak war R&D-Engineer bei XtremIO; Jeff Denworth kam von CTERA Networks. Und das Netzwerk spielt auch im Storage eine immer größere Rolle. Edge, composable disaggregated everything und Scale-Out-Architekturen erfordern schnelle Datentransfers zwischen Geräten, Standorten und Anwendern.
No more Tiers! – und auch keine Silos ☝️
Ein Designziel von VAST war es, dass jeder sich All-Flash-Storage leisten kann – auch im Petabyte-Bereich. Und es sollte ein Storage für alle und alles sein: VAST macht keinen Unterschied zwischen File-, Block- oder Objektspeicher.
Eine Besonderheit bei VAST ist, dass es keinen Unterschied zwischen File und Object gibt. Für uns sind das nur verschiedene Protokolle, um auf dieselben Daten zuzugreifen.
Sven Breuner, Field CTO International bei VAST
Im Wesentlichen wird das über einen Abstraktionslayer abgebildet – den VAST Element Store ↗. Anwender greifen über Standardprotokolle auf ihre Daten zu: Windows-User über SMB, Linux-/Unix-User über NFS und die Cloud via S3. Die Daten liegen in Enclosures, die sich beliebig erweitern lassen. Protokollserver sorgen dafür, dass Daten nicht nur sicher gespeichert, sondern vor allem schnell wiedergefunden werden.
Moderne Lösungen wie die von VAST vereinen die Eigenschaften und Vorteile eines parallelen File-Systems mit Features wie der typischen hohen Ausfallsicherheit von Enterprise NAS-Systemen. Und damit wird ein weiteres Designziel der Plattform offenbar: Weg mit den Silos! Was im Umkehrschluss nicht bedeutet, dass es auch keine Silo-Features mehr geben muss. Im Gegenteil: der Universal Storage unterstützt u. a. sowohl User- als auch Verzeichnis-Quotas.
Grenzenloses Wachstum
Viele der Beschränkungen herkömmlicher Storage-Ansätze beseitigt VAST in seinem Scale-Out-Hochleistungsspeicher mit Basistechnologien, die erst vor etwa fünf Jahren sinnvoll kommerziell nutzbar wurden. Dazu gehören günstige Hyperscale-Flash-SSDs, Storage Class Memory sowie serverless Computing oder stateless Container.
DASE: Disaggregated Shared Everything
DASE ↗ ist ein Scale-Out-Architekturkonzept mit cloud-native Ansatz, bei der Leistung und Kapazität komplett voneinander entkoppelt sind. Die Logik des Systems wird in zustandslosen Docker-Containern unabhängig vom Storage implementiert. Jeder einzelne dieser Container kann sich mit allen Medien in allen Storage Enclosures verbinden und sie verwalten. Jedes Element kann unabhängig skaliert werden.
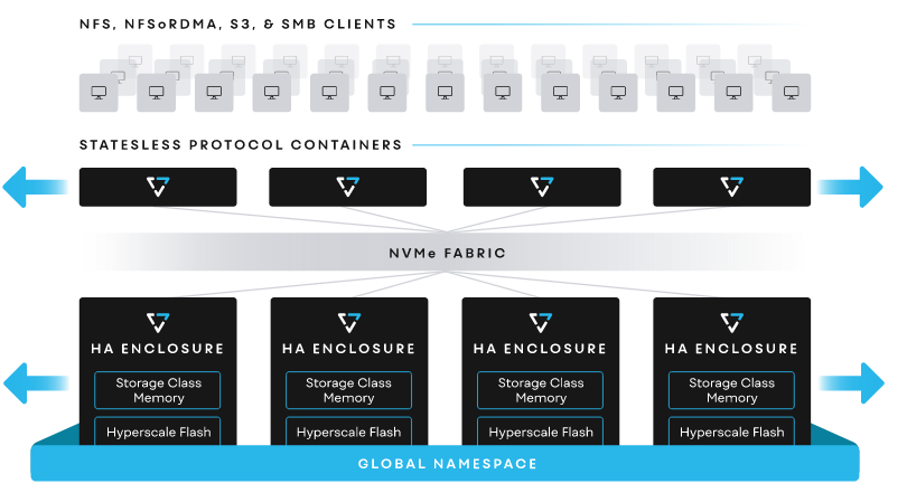
VAST sieht sich selbst als Software-Firma. Das Produkt ist als Container für Installationen in Cloud-Umgebungen oder als Appliance erhältlich. Damit VAST seine Magie entfalten kann, empfehlen wir das Komplett-Bundle: HA-Enclosures und Server-Appliances, auf denen die VAST-Container ausgeführt werden (Protokollserver) und die über NVMe-oF mit den Enclosures bzw. über NFS, SMB und S3 mit den Clients kommunizieren. Die Kommunikation in Richtung Clients basiert auf drei Kernelementen:
- RDMA für schnelle Zugriffe auf Dateien über das Netzwerk
- nconnect für einen besseren Durchsatz und mehr IOPS
- NVIDIA GPUDirect für direkte Datenpfade zwischen Storage und GPU-Memory
In den Enclosures setzt VAST auf Quad-Level-Cell-SSDs (QLC Flash). Höhere Kapazität und Dichte der QLC-SSDs sind auch ausschlaggebend für den günstigen Preis der Plattform. Der Preis pro Terabyte entspricht dem von HDDs (aka spinning disk) bzw. liegen mittlerweile oft sogar darunter. Storage Class Memory unterstützt bei Aufgaben wie dem large stripe write shaping, damit eben diese kostengünstigen SSDs effektiv genutzt werden können.
| ℹ︎ | QLC-NAND ist lese-optimiert. Viele kleine Schreibvorgänge mag es nicht. Daten verdaut es am liebsten in größeren Blöcken. Mit dem Storage Class Memory (SCM) werden kleine Datenhäppchen gesammelt, um sie später in größeren Blöcken auf die Drives zu verteilen. Das nutzt nicht nur den vorhandenen Platz wesentlich effektiver, es verlängert vor allem die Lebensdauer der SSDs. So ist es für VAST kein Problem, seinen Kunden 10 Jahre Garantie auf seine Appliances zu geben. |
Auch das ist ein Grund, das Komplettpaket von VAST zu kaufen. Erstens ist in den Enclosures des Herstellers das Verhältnis von SCM zu SSDs ausgewogen. Zweitens gibt es auch den Hardware-Support über VAST – Stichwort: Single point of contact.
| ℹ︎ | SCM ist auch als Persistent Memory, PMEM, oder non-volatile RAM, NVRAM, bekannt. |
Disaggregated ist bei VAST nicht nur die Architektur. Auch beim Preis macht das Startup die Dinge etwas anders. Mit Gemini können Anwender den Hardware-Kauf von den Kosten für die Software entkoppeln. Die Wartung der Hardware, einschließlich des Austauschs defekter SSDs, ist im Abo-Preis enthalten.
Datenlevel
VAST Enclosures beherbergen SCM- und Hyperscale-Flash-SSDs und sind über eine NVMe-Fabric über Ethernet oder InfiniBand untereinander und mit den Protokollservern verbunden. In der aktuellen dritten Generation (Ceres) übernehmen BlueField ↗-DPUs von NVIDIA die Beschleunigung von RDMA, Verschlüsselung und NVMe-oF. Die Smart NICs vereinen Netzwerk- und Server-CPU in einer Einheit. Das spart Platz im Gehäuse. Zudem verbrauchen die ARM-basierten Prozessoren wenig Strom und produzieren weniger Wärme. Letzteres wiederum stellt geringere Ansprüche an die RZ-Infrastruktur, allem voran die Kühlung. In jedem Enclosure stecken zwei DPUs. Überhaupt sind alle Fabric-Module, NICs, Lüfter und Netzteile redundant ohne einen single point of failure. In den Ceres-Gehäuse kommen SSDs im EDSFF E1.L-Formfaktor zum Einsatz, dem so genannten Ruler-Design. Die gibt es zur Zeit mit Kapazitäten ↗ bis 3,2 TB. In ein 1-HE-Enclosure passen 22 davon. Die eigentliche Intelligenz sitzt in den Protokollservern.

Intelligenzlevel
Alle Protokollserver in einem Cluster sehen immer alle Enclosures für einen globalen, direkten Zugriff auf alle Daten und Metadaten im System. Rechenintensive Operationen wie Erasure Coding oder Datenverwaltung und -reduzierung werden über alle CPUs im Cluster verteilt. Die Funktionen sind im VAST Server Operating System (VASTOS) zusammengefasst, welches in zustandslosen Containern bereitgestellt wird. Für ein Update oder Upgrade von VASTOS wird einfach ein neuer Container bereitgestellt, ohne dass das zugrunde liegende Betriebssystem neu gestartet werden muss. Die Zeit, in der ein VAST-Server offline ist, wird auf wenige Sekunden reduziert. Rollt man Updates kaskadierend im Cluster aus, spüren die User nichts davon.
Und wenn eine SSD doch mal kaputt geht, bekommen Anwender auch nichts davon mit. VAST speichert die Daten redundant mit Erasure Coding. Das sorgt auch dafür, dass nach dem Tausch einer SSD die Daten automatisch wiederhergestellt werden. Mit dem von VAST verwendeten Algorithmus können bis zu vier SSDs ausfallen, ohne das es zu einem Datenverlust kommt.
Vom Gesundheitszustand des Gesamtsystems und all seiner Komponenten können sich Admins jederzeit im übersichtlichen Dashboard der GUI überzeugen. Selbstverständlich generiert VAST auch einen Alarm im Fehlerfall. Diese werden dreistufig priorisiert: geringfügig, schwerwiegend und kritisch. Ein Alarm kann auch automatisch wieder verschwinden, z. B. wenn das Problem durch die automatisierte Wiederherstellungsfunktionen behandelt und gelöst wurde. Manche sagen auch Self-Healing dazu.
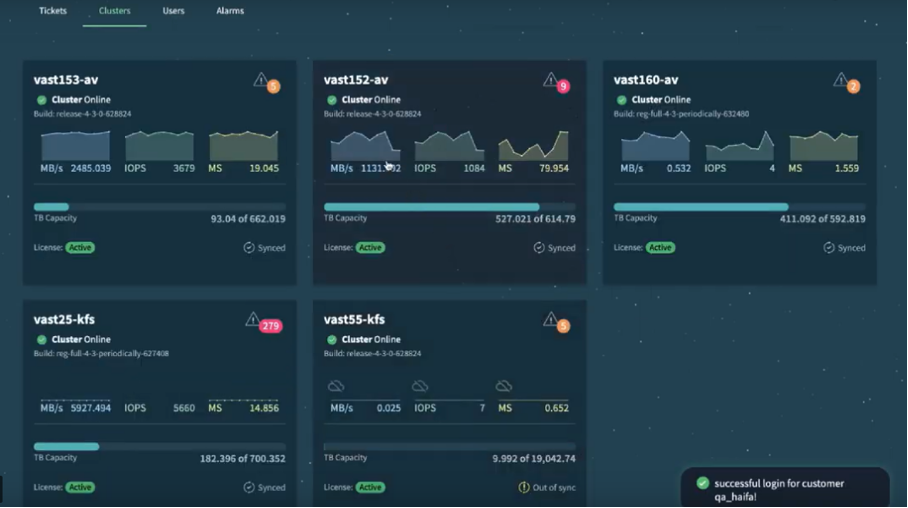
Die Protokollserver sind auch für die Lastverteilung über den gesamten Cluster zuständig.
Sicherheitslevel
Die Integrität der Daten wird mit Prüfsummen für jeden Daten- und Metadatenblock im System sichergestellt. Dabei speichert VAST die Checksummen nie im selben Block wie die Daten selbst. Damit wird nicht nur Bitrot vermieden. Der Datenpfad wird auch vor systeminternen Datenübertragungsfehlern geschützt.
VAST-Snapshots nutzen Zero-Copy-Mechanismen sowohl für Daten als auch für Metadaten und nutzen vorhandenen, freien Speicherplatz. Mit Snap to Object lassen sich Snapshots zudem an einen beliebigen S3-kompatiblen Objektspeicher replizieren.
Unzerstörbare Snapshots verhindern die Veränderung oder Löschung von Sicherungskopien durch böswillige Akteure inner- oder außerhalb des Unternehmens. Neben der Integration in gängige Plattformen wie Commvault oder Veeam unterstützt VAST auch Cloud-Technologie (Backup von Containern) sowie über eine Schnittstelle zu Model9 sogar die Sicherung von Daten in Mainframes.
Und damit sind wir auch schon bei den Use Cases angekommen.
Userlevel
Am besten eignet sich VAST für moderne Big-Data-Workloads wie Analysen, AI und Machine Learning sowie für Backups.
Backups sind vielleicht nicht so offensichtlich, aber in Bezug auf immer kürzere RTOs macht es durchaus Sinn. QLC-Flash in Kombination mit moderner Datenreduzierung (Similarity-Based Data Reduction) und hocheffizienten Erasure Codes bringen Flashspeicher auf ein auch für Backup geeignetes, wirtschaftliches Preisniveau mit bis zu 40 Prozent niedrigeren Kosten als herkömmliche Purpose-built Backup Appliances (PBBAs) wie z. B. Dells EMC PowerProtect DD.
Offensichtlicher sind lese-intensive AI-/ML- oder HPC-Workloads. Wenn Anwendungen schnell und ohne Latenz auf große Datenmengen zugreifen müssen, sind drehende Festplatten keine Option mehr. Mehr parallele Queues und ein geringerer Overhead in den Befehlssätzen machen NVMe-SSDs deutlich schneller als ihre SAS- oder SATA-Kollegen. NVMe over Fabrics (NVMe-oF) erweitert handelsübliche Ethernet- und Infiniband-Netzwerke um die PCI-Leistung.
Und warum jetzt keine Tiers mehr?
Die kurze Antwort ist: Weil sich Daten für AI-Workloads nicht vorhersagen lassen. Für AI und ML gibt es keine heißen oder kalten Daten. Es lässt sich schlicht und ergreifend nicht vorhersagen, auf welche Daten z. B. der Lernalgorithmus als nächstes zugreift. Und das ist auch gut so. Würden die Algorithmen nämlich nicht random access auf alle Daten haben, wäre der Lerneffekt für das Machine Learning ein sehr eingeschränkter.
Ähnliches gilt für HPC-Anwendungen wie Modellierung und Simulation sowie besonders leistungsfähige Datenanalysen. Es macht keinen Sinn, nur einen Bruchteil der vorhandenen Daten für diese Workloads zu nutzen und den Rest in irgendwelchen Gletschern einzufrieren.
Die Daten, die ich über die Zeit gesammelt habe – von meinen Kunden, im Unternehmen, sind quasi die Kronjuwelen. Und wenn ich mir diese Daten nicht anschauen, sie nicht analysieren kann, kann ich auch nichts aus ihnen lernen.
Sven Breuner über Nutzen von und Zugang zu Daten
Dazu kommen unterschiedliche E/A-Muster traditioneller HPC-Modellierung (kleine Dateneingänge/große Datenausgänge) und neuer AI/ML-Trainings- und Inferenzmustern (große Dateneingänge/kleine Datenausgänge). Da im Zuge von Digitalisierung Organisationen immer öfter beides brauchen, muß auch die Speicherinfrastruktur beiden Anforderungen gleichzeitig genügen ↗. Egal ob Industrie, Finanzdienstleistungen, Behörden, Gesundheitswesen, Bildung, Forschung & Lehre, Medien und Unterhaltung oder Telekommunikation – jede Branche will die Chancen neuer Technologie nutzen. Als Stichworte seien nur digitaler Zwilling, predictive Analysis, generative AI und Natural Language Processing (NLP) oder Data-in-Motion genannt.
VASTs Universal Storage ist die erste Network Attached Storage (NAS)-Lösung mit einer Zertifizierung für NVIDIAs DGX SuperPOD ↗.
Transaktionshungrige Branchen wie Banken, Versicherungen oder Einzelhandel profitieren noch auf eine ganz andere Weise von VAST. Teile der Queries von SQL-Datenbanken können von VAST bereits vorbearbeitet werden, so dass die Ergebnisse schneller bereitgestellt werden können und auf Anwendungsseite weniger CPU-Leistung beansprucht wird. Möglich macht das u. a. Trino ↗, eine verteilte SQL-Abfrage-Engine für Big Data-Analysen in einem Datenuniversum.
Roadmap
Auch für VAST spielen Daten am Edge und über verschiedene Rechenzentren verteilte Informationen eine Rolle. Und auch hier geht das Unternehmen neue Wege. Mit Constellations soll es bald möglich sein, Daten bei Bedarf vom Speicherort auf den Ort, wo sie benötigt werden, zu projizieren.
Das funktioniert auf dem Prinzip von In-Memory-Computing. Die Daten werden in einen nicht-volatilen (persistenten) Cache geladen, wo sie auch bearbeitet werden. Es wird zu keiner Zeit eine Kopie benötigt. Änderungen werden an den Originaldaten gepflegt.
Datenkatalog und angereicherte Metadaten im SQL-Format erleichtern die Suche im Cluster.
Wir sprachen mit Sven Breuner, Field CTO bei VAST, auf der ISC 2023 in Hamburg.

