Im Bereich Wissenschaft und Forschung fallen über lange Zeiträume große Datenmengen an. Die meisten Daten werden aus Kostengründen auf Tapes oder in eisige Cloudspeicher ausgelagert. Neue Erkenntnisse oder Technologie ermöglicht neue Einsichten. Dann müssen die Daten wieder aktiviert werden. Das ist nicht immer einfach. Oft weiß keiner mehr, dass die Daten überhaupt existieren oder wo sie sich befinden. Die Extraktion bestimmter Informationen für neue Analysen ist ebenfalls für viele Wissenschaftler eine Herausforderung.
Nodeum automatisiert die Datenmigration in hybriden Storage-Landschaften, um Mehrwerte aus dem Datenozean zu generieren und neue Geschäftsmodelle zu ermöglichen. Das belgische Startup ist auf die Übertragung großer Mengen unstrukturierter Daten spezialisiert.
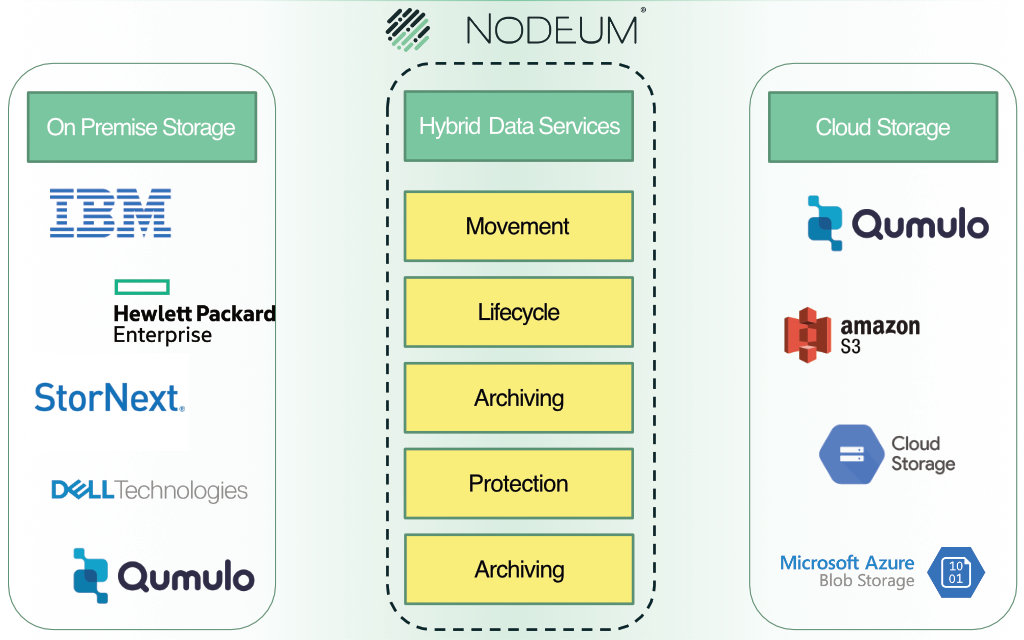
Die Zielgruppe von Nodeum sind vor allem Wissenschaftler und Forschende, die oft über lange Zeiträume Daten sammeln und auswerten müssen. Medienschaffenden können der Plattform ihre Datenströme in Post-Production-Workflows automatisieren. Aber auch Unternehmen profitieren von den Vorteilen einer Migrationsplattform wie dem Data Mover. AI und ML sind datenhungrige Anwendungen: je mehr Informationen ihnen zur Verfügung stehen, desto besser funktionieren sie.
Das Potential aller Daten nutzen
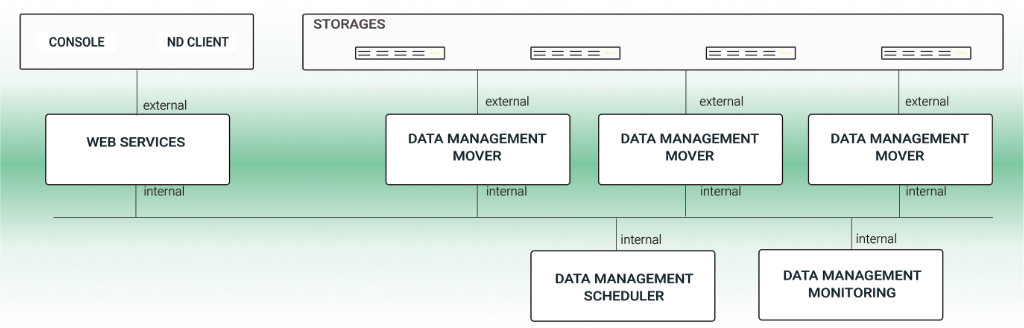
Ein einheitlicher Namensraum und die zentrale, intelligente Metadatenverwaltung sind die Grundvorraussetzung für eine Tier-übergreifende, langfristige Nutzung und Verarbeitung von Daten. Der Data Mover 🌐 von Nodeum bietet aber noch mehr.
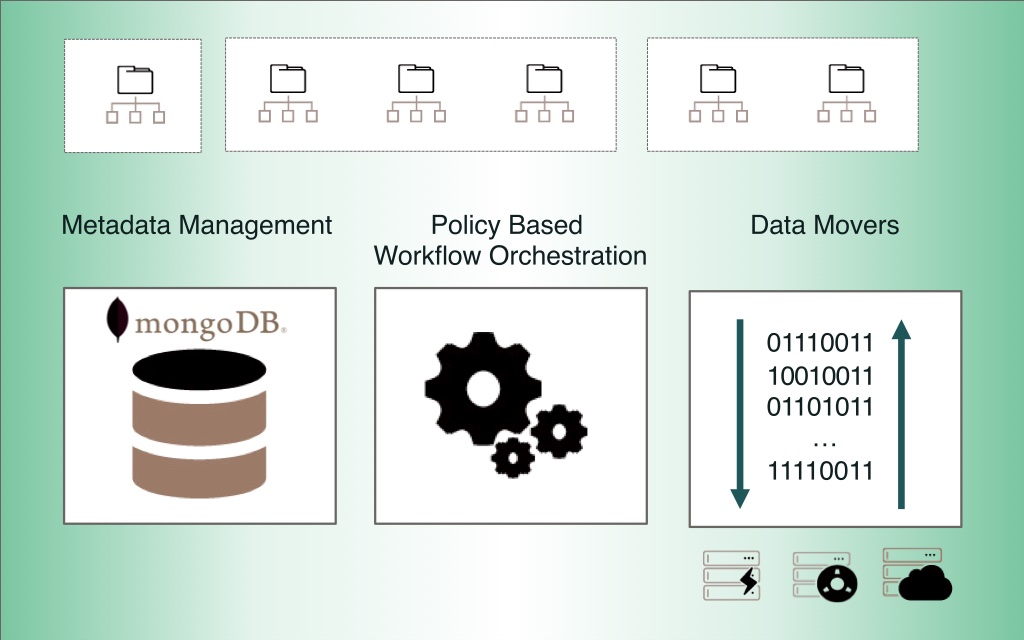
Eine integrierte Suchmaschine verkürzt die Zeit für das Finden von Daten. Mit No- bzw. Low-Code können talentierte Anwender individuelle Workflows im Datenmanagement gestalten oder eigene Skripte integrieren. Standardisierte, programmierbare Schnittstellen (API) und ein SDK erleichtern die Integration mit nutzerspezifischen Anwendungen.
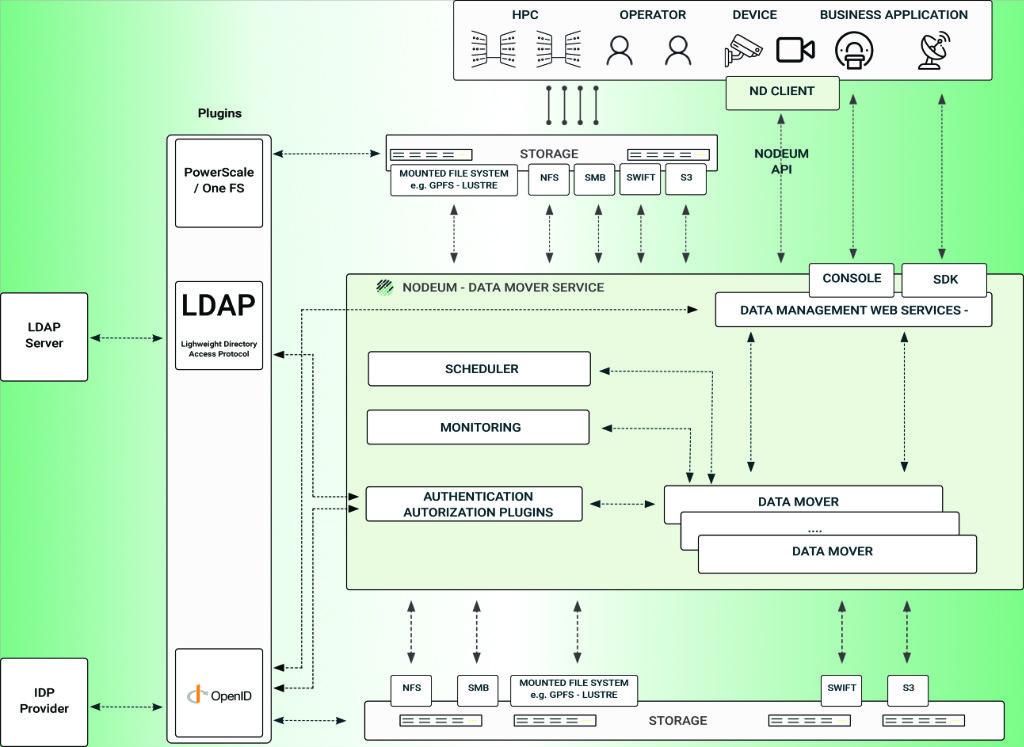
Zur Verwaltung können wahlweise eine Web-GUI oder der integrierte Bash-Client (Nodeum Console) verwendet werden. Im Monitoring lässt sich der Status von Datenbewegungen in Echtzeit verfolgen. Das Reporting erlaubt die Auswertung von Workflows im Laufe der Zeit für z. B. Optimierungen.
Datenbewegungen automatisieren
Der direkte Benutzerzugriff auf verschiedene Ebenen aller genutzten Datenspeicher und die Integration mit Workload-Managern wie SLURM sollen Datenbewegungen zwischen HPC-, Supercomputing- oder Cloud-Ressourcen so einfach und sicher wie möglich machen.
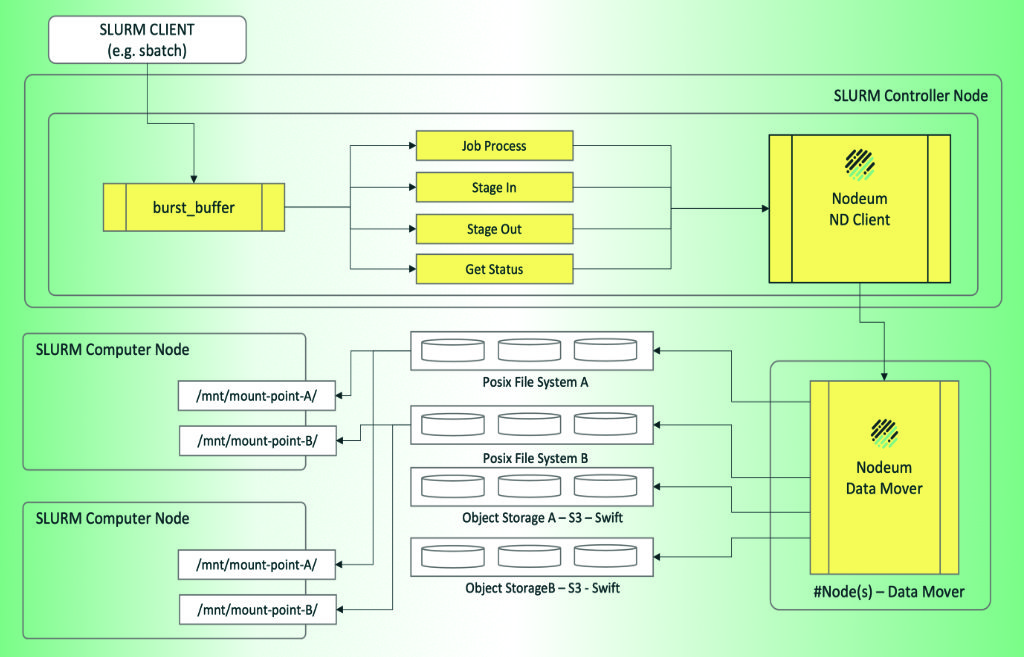
Die Verarbeitung unstrukturierter Daten findet zudem immer öfter direkt dort statt, wo Daten erzeugt werden. SLURM-Benutzer können Tasks für den Data Mover auch direkt am Edge planen.
Nodeum ist horizontal und vertikal skalierbar. Mehr Mover-Knoten erhöhen den Bewegungsdurchsatz. Zusätzliche Ressourcen innerhalb eines Knotens erlauben die Ausführung zusätzlicher Mover-Dienste.
Keine halben Sachen
In der IT ist alles entweder 0 oder 1. Das gilt selbst für Quantenrechner. Im Fall von Nodeum bedeutet es, dass eine Datei oder ein Objekt entweder vollständig oder gar nicht übertragen wurde. So verhindert die Plattform das Speichern fehlerhafter, unvollständiger oder fragmentierter Datensätze.
Die Ausführung einer Aufgabe kann selbstverständlich jederzeit angehalten und später fortgesetzt werden. Das ist nützlich bei unerwarteten Problemen oder lang laufenden Übertragungen, die mehrere Stunden oder sogar Tage dauern können. Ein Task kann an der Stelle neu gestartet werden, an der es unterbrochen wurde.
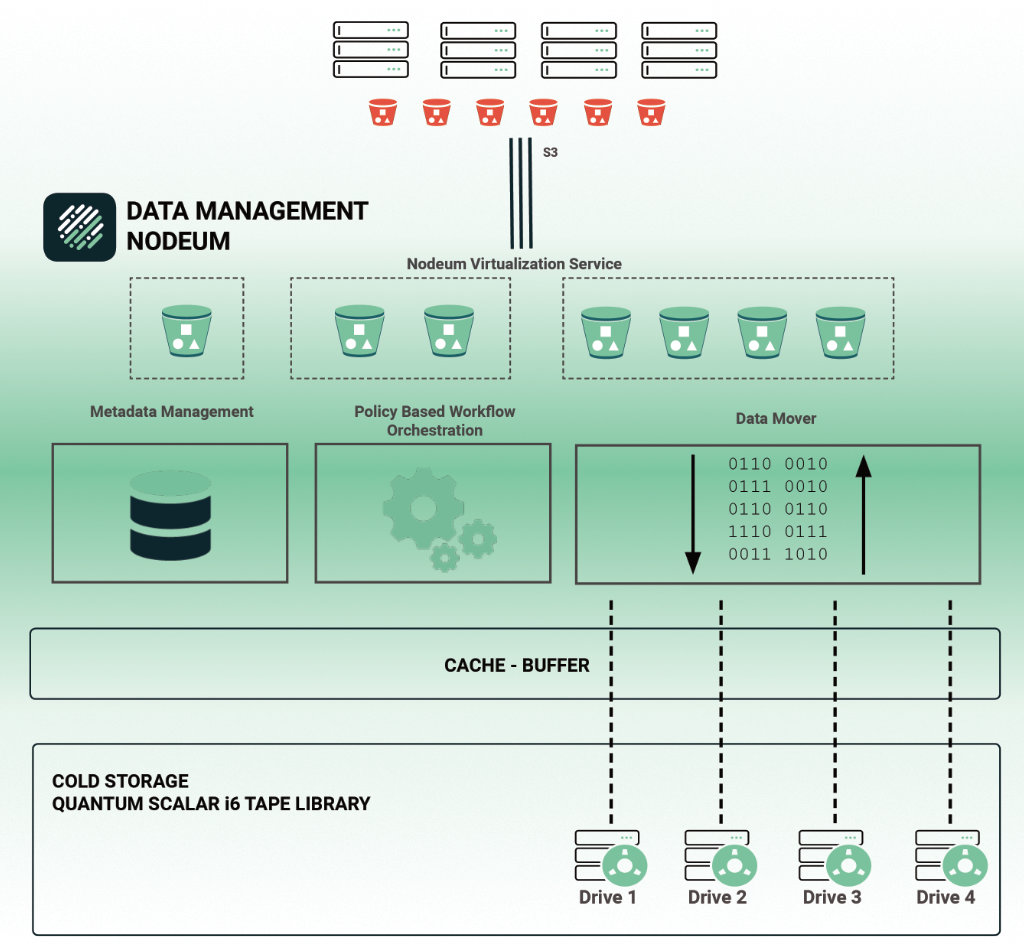
Der Data Mover verwendet eine Kombination von Techniken, um die Integrität und Vollständigkeit der Daten zu überprüfen. Zu diesen Techniken gehört u. a. die Verwendung von Prüfsummen. Die erste Prüfung findet während der Übertragung der Daten von der Quelle zum Ziel statt. Kontinuierliche Integritätsprüfungen der archivierten Daten stellen sicher, dass die am Zielort gespeicherten Daten korrekt sind, nicht beschädigt wurden oder gar verloren gegangen sind.
Die Demokratisierung der Datenbewegung
Eine implementierte Prioritätsverwaltung verhindert, dass Workflows mit der höchsten Priorität den gesamten verfügbaren Durchsatz verbrauchen und andere Workflows auf unbestimmte Zeit warten lassen. Quality of Service (QoS) stellt sicher, dass kritische Workloads die erforderlichen Ressourcen erhalten, gewähren aber auch nicht-kritischen Übertragungen einen fairen Zugang. Dazu werden kritischen Anfragen bestimmte Ressourcen zugewiesen und gleichzeitig sichergestellt, dass jede andere Anfrage einen gleichen Anteil an den verbleibenden Ressourcen erhält. So kann kein Data-Mover-Workflow alle verfügbaren Ressourcen in Anspruch nehmen. Alle Workflows erhalten einen fairen Zugang zu den vorhandenen Ressourcen.
Aufgaben können mit Richtlinien definiert und optimiert werden. So lassen sich bestimmte Tasks außerhalb der Stoßzeiten oder nur bei ausreichend verfügbaren Ressourcen einplanen. Einfache und erweiterte Filteroptionen erlauben die Verwaltung und Organisation von Arbeitsabläufen für die Datenübertragung. Benutzer können eigene Filter einrichten, die Dateien auf der Grundlage von Größe, Erstellungsdatum, Änderungsdatum, Dateityp und mehr automatisch aus- oder einschließen. Auch Kombinationen sind möglich, um komplexere Workflows abzubilden.
Nodeum beschleunigt die Beziehungen zwischen Maschinen und Menschen.
Valéry Guilleaume, CEO und Mitgründer von Nodeum
Beispiele aus der Praxis
Die verpflichtende gemeinsame Nutzung von Daten und die FAIR 🌐-Datenverwaltung erhöht die Anforderungen der Superrechenzentren an moderne Dateninfrastrukturen und stellt viele HPC-Anwender vor neue Herausforderungen. Der Data Mover vereinfacht die Datenübertragung mit standardisierten Schnittstellen.
Zu den ersten Referenzen in Deutschland gehört das Forschungszentrum in Jülich 🌐. Dort bewegt der Data Mover mit hoher Geschwindigkeit Daten sicher zwischen den HPC-Filesystemen und einem Objektspeicher – POSIX-konform und unter Verwendung einer SWIFT-API. Forschende können den Dienst programmieren und mit eigenen Skripten erweitern.
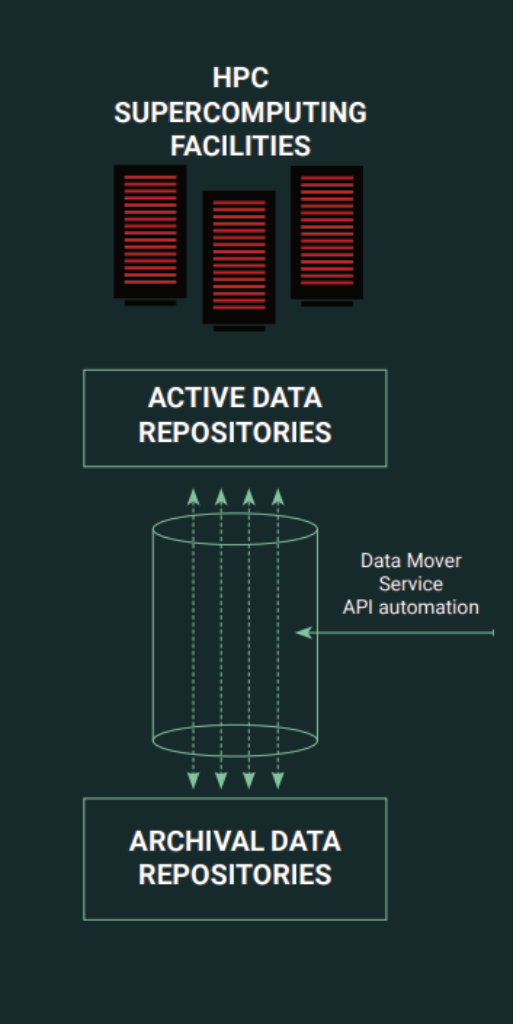
Die Herausforderung von Forschungszentren wie dem FZJ ist die Speicherung der generierten Inhalte in Repositories, die nahe beieinander liegen und gut integriert sind. Als Speicherebenen werden zwei Kategorien von Repositories verwendet:
- Active Data Repositories liefern die Leistung, wenn Daten von Supercomputing-Systemen geschrieben werden
- Archival Data Repositories nutzen Schnittstellen, die in Cloud-Systemen verwendet werden und eignen sich für die gemeinsame Nutzung von Daten
Die Universität Rostock setzt den Data Mover zur Verwaltung der heterogenen Speicherlandschaft ein und erweitert die 3-2-1-Regel bei der Archivierung um Technologie- und Medienbrüche.
Wir halten es für wichtig, neben der optimierten Datenstruktur innerhalb und zwischen unseren heterogenen Systemlandschaften auch mehr Sicherheit und einen zusätzlichen Medienbruch zum Schutz unserer Daten im Rahmen unserer Datenspeicherungsmechanismen zu implementieren. Der Einsatz des komfortablen und technisch ausgereiften Data Movers von NODEUM® sichert uns Effizienz und Datensicherheit durch die individuelle Verknüpfung unserer Datenquellen, auch über APIs und unter Berücksichtigung aller Rollen- und Berechtigungsmodelle.
Malte Willert, Universität Rostock, IT- und Medienzentrum, Fachbereich 2: Systeme und Dienste, Projektleiter für die Einführung von NODEUM®
Auch die Medizinische Universität Graz nutzt den Data Mover. Dort war die Anforderung der Aufbau eines zentralen Archivs mit von einem Hochdurchsatz-Scanner erzeugten, digitalisierten pathologischen Daten. Der Nodeum Data Mover verkürzt die Zeit für die Analyse jedes einzelnen Objektträgers. Das verbessert nicht nur die Nutzung der teuren medizinischen Hardware. Auch die Art der Erkrankung kann schneller bestimmt werden.
Weitere Anwendungsbeispiele und Referenzen sind auf der Website 🌐 des Herstellers aufgeführt.
Der Data Mover ist als VM-, Container- oder ISO-Image verfügbar. Die Preise starten bei 149 USD pro Monat. Der Data Mover kann in Deutschland über SVA bezogen werden. Für weitere Optionen kann der Hersteller kontaktiert 📧 werden.
Wir trafen Valéry Guilleaume im September 2022 im Rahmen der IT Press Tour in Paris und im Mai 2023 auf der Technology Live! in München.

