Auf der ISC 2023 in Hamburg spielten drei Dinge eine wesentliche Rolle: Quantencomputer, Flüssigkühlung und AI. Der Markt für künstliche Intelligenz (KI) gewinnt aktuell massiv an Dynamik. Unternehmen jeder Größe investieren in KI-gestützte Lösungen. KI-Systeme für große und komplexe Workloads sind dabei oft über disaggregierte Rechen- und Speicherknoten verteilt.
AI-Workloads nutzen leistungsfähige Vektor-Prozessoren (GPU) für Berechnungen und Analysen. Für schnelle Zugriffe auf die Daten setzen sich zunehmend All-Flash-Lösungen wie die von VAST Data durch. Eine Herausforderung ist jedoch die Verbindung zwischen GPUs und Storage.
Für leistungsstarke Verbindungen in diesen auch als KI-Netzwerk bezeichneten Strukturen wurde in der Vergangenheit oft Infiniband eingesetzt. Modernere Netzwerklösungen unterstützen Standardkonnektivität wie Ethernet. Das verbessert die Interoperabilität verschiedener Anbieter. Damit die teuren KI-Rechenressourcen optimal genutzt werden können, fokussieren sich Anbieter wie DriveNets auf die Entwicklung hochspezialisierter Netzwerk-Fabrics.
Mit der Unterstützung einer Vielzahl von White Boxes, NOCs und AI ASICs vermeiden Anwender Vendor-Lock-ins. Basierend auf dem Konzept des Open Compute Projects (OCP) erhalten Kunden zudem eine nachhaltige, Ressourcen-optimierte Lösung.
Nachhaltigkeit ist heute ein zentrales Thema. Das Bewusstsein für den wirtschaftlichen Wert und die umweltkritischen Auswirkungen ist gestiegen. Service Provider wissen um die betriebliche Einfachheit und die Kosteneinsparungen, die durch die Optimierung des physischen Footprints, die Verlängerung des Lebenszyklus des Netzwerks und die Optimierung der Ressourcennutzung erzielt werden können. DriveNets verbessert die Nachhaltigkeit der größten Netzwerke der Welt – eine nicht triviale Wirkung.
Run Almog, Head of Product Strategy bei DriveNets
KI-Cluster sind vergleichbar mit einem Supercomputer. Für die Ausführung komplexer, umfangreicher KI-Aufgaben bestehen diese Systeme aus bis zu mehreren Tausend Compute Nodes. Ein KI-Cluster kann aus bis zu 32.000 GPUs bestehen. Die KI-Netzwerkinfrastruktur muss mehrere Tausend Hochgeschwindigkeits-Ports (400 und 800 Gbps) unterstützen. Allein diese Saklierbarkeit liegt jenseits jeder Gehäusegrenze.
In großen Clustern kommen vor allem teure Enterprise-grade GPUs zum Einsatz. Aus Gründen der Wirtschaftlichkeit sollte daher eine hohe Auslastung gewährleistet sein. Leerlaufzeiten beim Warten auf Netzwerkressourcen sind weder wirtschaftlich noch zweckdienlich. Eine vorhersehbare und verlustfreie Kommunikation ist die Voraussetzung für eine optimale GPU-Auslastung und eine maximale JCT-Leistung (Job-to-Complete-Ratio).
Multicloud, Edge, Software-Overlays und temporäre Dritt-Ressourcen sorgen für eine zunehmend heterogene Infrastruktur. Ein verbindendes Element wie das Netzwerk sollte daher möglichst interoperabel sein und auf einer offenen Architektur basieren.
Flaschenhälse verbrennen Geld und Mitarbeiter
Seit jeher treiben neue Anwendungen die Entwicklung immer schnellerer Netzwerkwerke voran. AI ist so eine neue Anwendung. Neue Anwendungen wie KI, die Verarbeitung natürlicher Sprache (NLP) und maschinelles Lernen offenbaren neue Lücken in der Architektur. In großen KI-Clustern hängt die Geschwindigkeit des Rechenprozesses stark davon ab, wie schnell ein Prozessor auf die auf Informationen von einem Grafikprozessor im selben Cluster zugreifen kann.
Für die optimale Auslastung gilt es, Flaschenhälse zu eliminieren bzw. zu vermeiden. Ein langsames Netzwerk ist ein solcher Flaschenhals. Die Folge sind Wartezeiten: Die Anwendung wartet auf Daten. Der Anwender wartet auf Ergebnisse. Mitarbeiter, die aufgrund langsamer Anwendungen zur Untätigkeit verdammt werden, sind unproduktiv. Das macht auf Dauer unzufrieden. Sind Kunden von langen Wartezeiten oder schlechtem Service betroffen, leidet das Ansehen des Unternehmens.
Es ist aber auch ein unkalkulierbarer wirtschaftlicher Faktor. Die zunehmende Verbreitung von KI machen GPUs zu einem begehrten Stück Hardware. Die Preistendenz ist eher steigend, eine Entspannung nicht in Sicht. Nutzt ein Unternehmen seine Investition in GPUs nicht optimal, ist es ein wirtschaftlicher Verlust und wirkt sich zudem negativ auf die Gemeinwohlbilanz (ESG) aus.
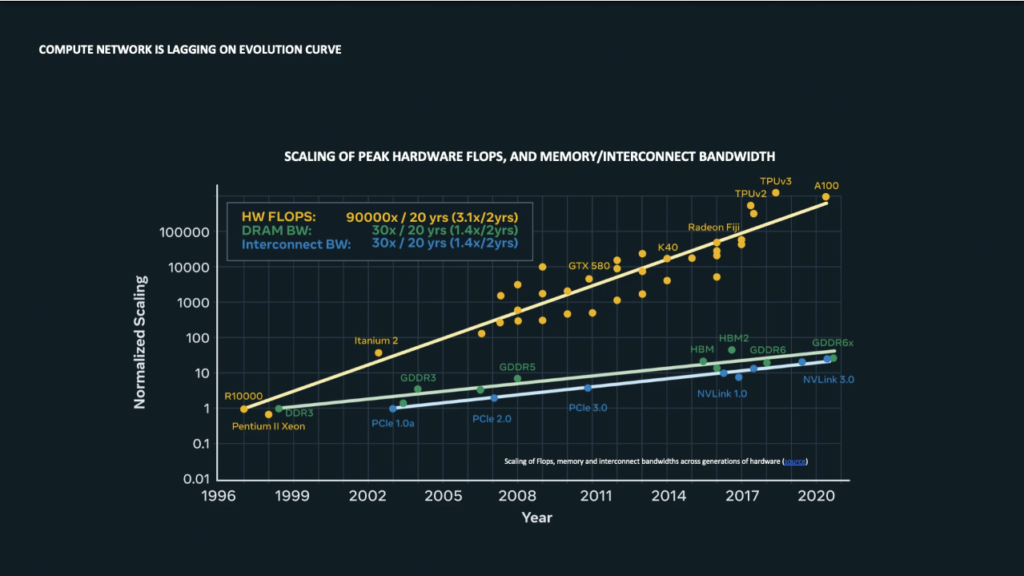
Die Verarbeitungsgeschwindigkeit der Hardware (FLOPS) wächst stärker als die Geschwindigkeit der Vernetzung. Latenz, Jitter oder Paketverluste in der Inter-Server- bzw. Inter-CPU-GPU-Konnektivität führen zu Leerlaufzyklen der GPUs. Alexis Bjorlin, VP of Engineering Infrastructure bei Meta, beschreibt in ihrer Keynote auf dem OCP Global Summit 2022 den Engpass zwischen der Rechenleistung/Kapazität (in FLOPS) und der Bandbreite des Speicherzugriffs.
Speziell für die Anforderungen von KI-Workloads entwickelte Fabrics wie die von DriveNets adressieren diesen Engpass. Im Bereich Storage kennt man das Konzept der Fabrics schon länger mit NVMe-oF. NVMe verbindet die Vorteile von PCI und RDMA in einem Protokoll und sorgt so für eine nahezu latenzfreie Kommunikation zwischen Prozessor und Speicher.
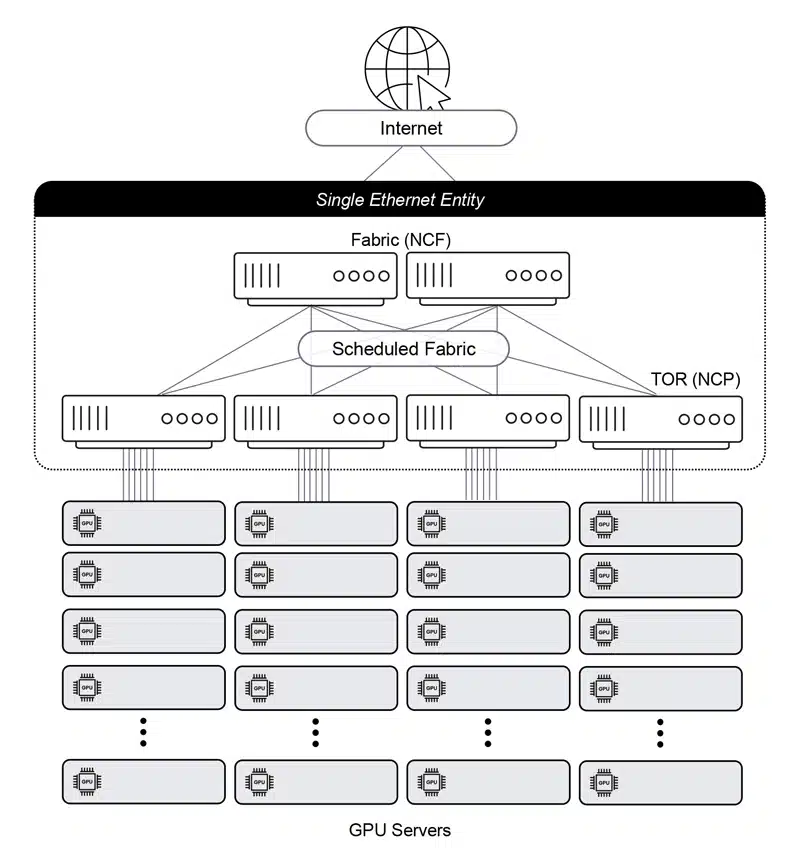
DriveNets AI-Netzwerk-Fabric ist Software-Defined. Mit der eigenen Cloud-AI kann DriveNets Netzwerkanforderungen vorhersagen und sorgt für die optimale Nutzung der KI-Beschleuniger (GPUs). Dabei setzt das kalifornische Startup auf einen alten Bekannten: Mit 600 Mio. Ethernet-Ports pro Jahr ist Ethernet das am meisten verbreitete Protokoll und der De-facto-Standard. Standardschnittstellen ermöglichen „Mix & Match“ unterschiedlicher Anbieter. Die innovative Architektur verbindet Skalierbarkeit von Fabric-Interconnect-Lösungen mit der Kosteneffizienz eines offenen, disaggregierten Cloud-Modells für eine verlustfreie Konnektivität, niedrige Latenz und geringen Jitter. Um das zu erreichen, fasst DriveNets die herkömmliche mehrstufige Clos-Architekturen (ToR/Leaf-Spine/Super-Spine) in einer flachen Single-Switch-Architektur mit Inter-Rack-Konnektivität zusammen.
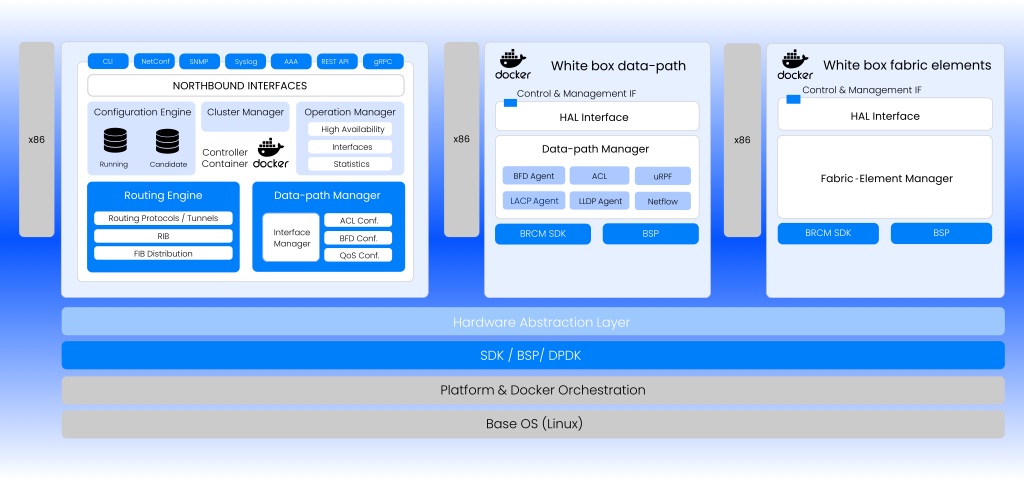
DriveNets ermöglicht ein vertrauenswürdiges Ökosystem mit offenen, standardisierten Schnittstellen, die sie nahtlos und wirtschaftlich in eine bestehende Infrastruktur integrieren. Die offene Architektur gewährleistet den Betrieb auf jeder Network-Cloud-zertifizierten Hardware-Plattform. Unternehmen sind mit DriveNets AI-Networking-Cloud nicht mehr nur auf NIVIDIAs InfiniBand-Technologie beschränkt, die ausschließlich Nvidia-GPUs unterstützt (Vendor-Lock-in).
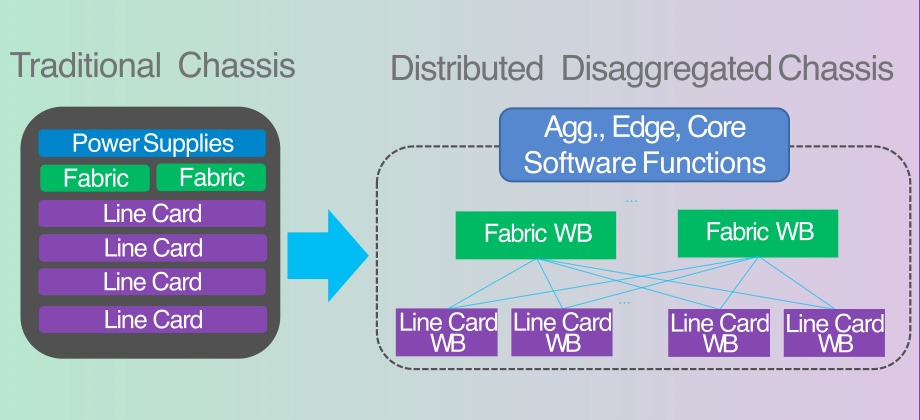
Distributed Disaggregated Chassis (DDC) für die Back-End AI Networking Fabric
Auch die Entwicklung von Distributed Disaggregated Chassis 🌐 (DDC) trägt den besonderen Netzwerkanforderungen von KI-Workloads Rechnung. Als Back-End einer AI Networking Fabric erlauben DCCs eine z. B. rackübergreifende Verbindung von CPUs und GPUs mit der gleichen Geschwindigkeit und Leistung die man vom internen I/O-Bus (PCIe oder NVLink zwischen GPUs) kennt.
DriveNets unterstützte als erste Lösung AT&Ts Distributed Disaggregated Chassis 🌐 (DDC) Architektur basierend auf dem Open Compute Project (OCP). Heute gehört AT&T zu den größten Anwendern des 2015 gegründeten Unternehmens. Der Carrier nutzt DriveNets Network Cloud-Technologie für seine softwarebasierte Core-Routing-Technologie.
Der Teil, den wir von DriveNets verwenden, ist in unserem Kern-Backbone. Wir übertragen
Yigal Elbaz, CTO Network Services bei AT&T (Quelle: DriveNets)
590 Petabytes pro Tag. Das ist eine Menge Verkehr auf unserem Kern-Backbone. Bereits jetzt
laufen bereits über 50% des Datenverkehrs über die offene, disaggregierte Architektur mit dem Netzwerkbetriebssystem von DriveNets.
Flexibel und Skalierbar
Ursprünglich entwickelte DriveNets seine Network-Cloud für den Einsatz für die carriergrade Netze von Telcos und ISPs. Inspiriert von den KI-Beschleunigerplattformen der Hyperscaler optimierte das findige Startup seinen Ansatz für KI-Workloads. DriveNets Network Cloud-AI basiert auf der DriveNets Network Cloud und wurde entwickelt, die Auslastung von KI-Infrastrukturen zu maximieren.
Mit seiner Network Cloud geht der Israelische Netzwerkspezialist auch wirtschaftlich neue Wege: Netzwerkdienste auf Basis einer gemeinsam genutzten Infrastruktur von White Box Clustern in einem Infrastructure-as-a-Services (IaaS)-Modell erlauben eine optimale Skalierung von einem einzelnen Router (4 Tbps) bis hin zu Clustern mit Hunderten von White Boxes (768 Tbps). Das eröffnet Service Providern neue Geschäftsmodelle, z. B. KI-Cluster-as-a-Service. Auch auch ISPs oder Webhoster profitieren von der schlankeren, flexibleren Infrastruktur.
Die Cloud-native Architektur von DriveNets ermöglicht es, mehrere Netzwerke in separaten Software-Containern auf einem gemeinsamen Ressourcenpool zu betreiben. Jede Netzwerkfunktion kann alle zugrundeliegenden Hardwareressourcen nutzen, wie z. B. physische Schnittstellen, Network Processing Units (NPUs), CPUs oder sogar Ternary Content-Addressable Memory (TCAM). Damit können z. B. sowohl ein Core-Router als auch ein Peering-Router auf demselben Cluster eingesetzt werden und trotzdem als zwei individuelle Entitäten arbeiten. Darüber hinaus ist der Netzwerk-Cluster nicht auf Netzwerkfunktionen beschränkt. Z. B. kann eine Firewall als zusätzlicher, separater Container denselben zugrunde liegenden Ressourcenpool nutzen.
Unterstützt werden verschiedene Chip-Hersteller und White Box ODMs inkl. optischer Geräte. Die Lösung besteht aus dem DriveNets Network Operating System (DNOS), dem DriveNets Network Orchestrator (DNOR) und Whiteboxes jeweils für Line-Card- und Fabric-Funktionalität (NCP/NCF).
DNOS ist ein verteiltes NOS für eine einheitliche gemeinsame Infrastruktur über eine verteilte Architektur, darunter Core, Aggregation, Peering, Edge und Access Routing. Mit dem DNOR lassen sich Bereitstellung, Skalierung und Verwaltung der DriveNets Network Cloud-Lösung in verteilten, herstellerübergreifenden disaggregierten Netzwerken automatisieren.
Wir trafen Run Almog, Head of Product Strategy, und Dudy Cohen, VP Product Marketing, auf der ISC HP 2023 in Hamburg.



