Latenz ist Verzögerung. Jeder kennt die Wartezeit beim Aufruf einer Webseite bis zur Anzeige und dem Laden aller Inhalte. Je schneller etwas lädt, desto besser ist die Nutzererfahrung. Das trifft auch im Unternehmen zu. Dort sind es vor allem Datenbankeinträge oder Dokumente, auf die möglichst schnell zugegriffen werden muss. Dauert es zu lang, sinkt die Mitarbeiterzufriedenheit und irgendwann auch die Produktivität. Latenz kann auch geschäftskritisch sein. In Suchmaschinen werden oft die Ergebnisse mit den schnellsten Ladezeiten zuerst angezeigt. Ist man nicht unter den ersten zwei, passiert die Conversion woanders; es werden wertvolle Verkaufschancen verspielt.
Dell Technologies und seine Partner haben der Latenz den Kampf angesagt. Wir konnten uns auf dem TFDxDell21 davon überzeugen. Aber zunächst ein paar Grundlagen.
Hinweis für IT-Manager oder Budgetverantwortliche: Wenn Ihr Hardware kauft oder eine Architektur plant, müsst Ihr nicht super-detailliert wissen, was sich unter der Haube befindet. Aber Ihr solltet Eure Techniker verstehen und wissen, wie man die Spreu vom Weizen trennt bzw. welche Fragen Ihr den Herstellern stellen solltet, um keinen Marketing-Mist zu beschaffen.
Woher kommt Latenz?
Jede Anwendung – so unterschiedlich sie auch sein mag – hat eine Gemeinsamkeit: Je mehr Daten bewegt werden müssen, desto langsamer reagiert sie. Dabei ist es irrelevant, ob es sich um Lese- oder Schreibzugriffe handelt.
Eine große Rolle spielt die Entfernung, welche die Daten überwinden müssen. Auch die Kombination aus eingesetzter Hard- und Software ist nicht unwichtig. Relevant sind darüber hinaus die verwendeten Netzwerkprotokolle und die Wahl der eingesetzten Speichermedien. Serialisierung trägt ihr Übriges bei. Dabei werden Objekte in Bytefolgen umgewandelt, um sie über ein Netzwerk zu übertragen oder in Dateien zu speichern. Klassische, proprietäre Scale-Out-Architekturen sind dem ganzen genauso hilflos ausgeliefert wie modernere Cloud-Technologie, z. B. Ceph.
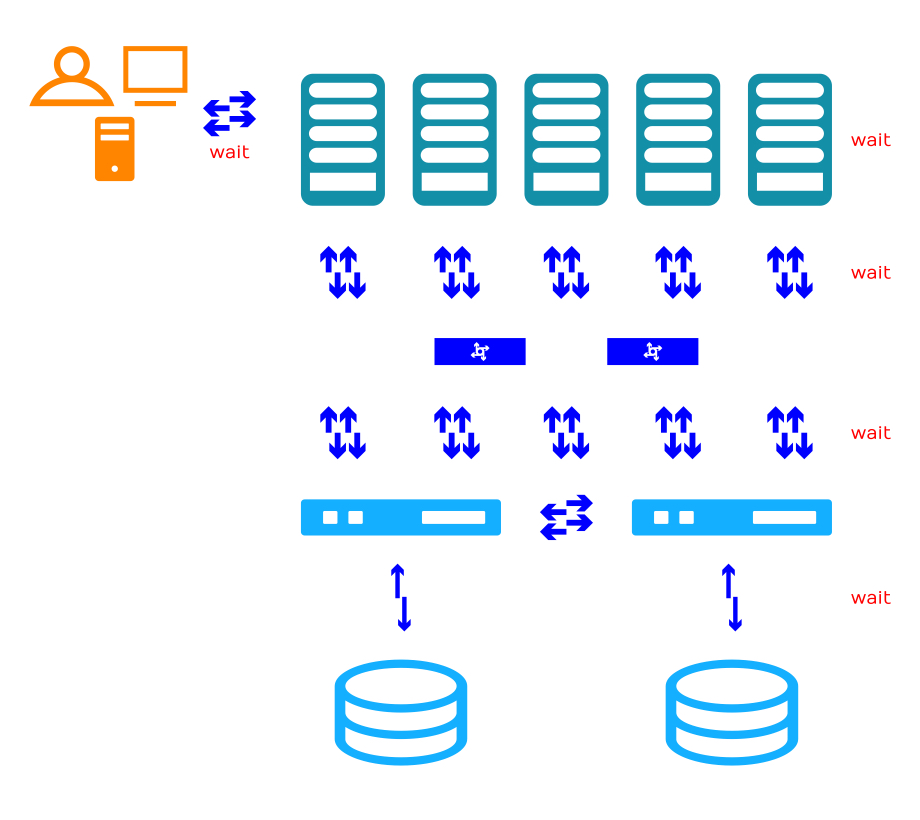

Jedes wait erhöht die Latenz um durchschnittlich 5 Millisekunden.
Oversize me
Zunächst einmal läßt sich schlechte Latenz hervorragend mit einem Fokus auf IOPS und Durchsatz kaschieren. Sowohl Cloud Service Provider (CSP) als auch Hersteller greifen gern darauf zurück. Der Trick heißt Overprovisioning: Die Physik wird mit Blech erschlagen.
Beim Overprosioning sind mehr Ressourcen vorhanden, als eine Anwendung benötigt – der Auslastungspunkt ist höher als der tatsächliche Workload. Diese Verschwendung hat gleich mehrere Nachteile:
- Es ist teuer.
- Es skaliert nur bedingt.
- Es benötigt mehr Platz.
- Es verbraucht mehr Strom.
- Es benötigt mehr Infrastruktur inkl. Kühlung.
Das Ganze gleicht einem Fass ohne Boden. Neben den Anschaffungs- steigen auch die Betriebskosten. Von den Folgen für die Umwelt fange ich erst gar nicht an.
Es lohnt sich also, beim Übertragungsweg anzusetzen. Bypässe und spezialisierte Protokolle haben direkten Einfluss auf die Geschwindigkeit.
Ich kenne da eine Abkürzung
Jedes Betriebssystem hat mehrere Speicherebenen (Storage-Stack). Auf Blockebene gibt es bereits einige gute Ansätze. Die meisten Anwendungen verwenden jedoch den Datei- oder Datensatzzugriff und können nicht direkt auf die Blockschnittstelle (Block-API) zugreifen.
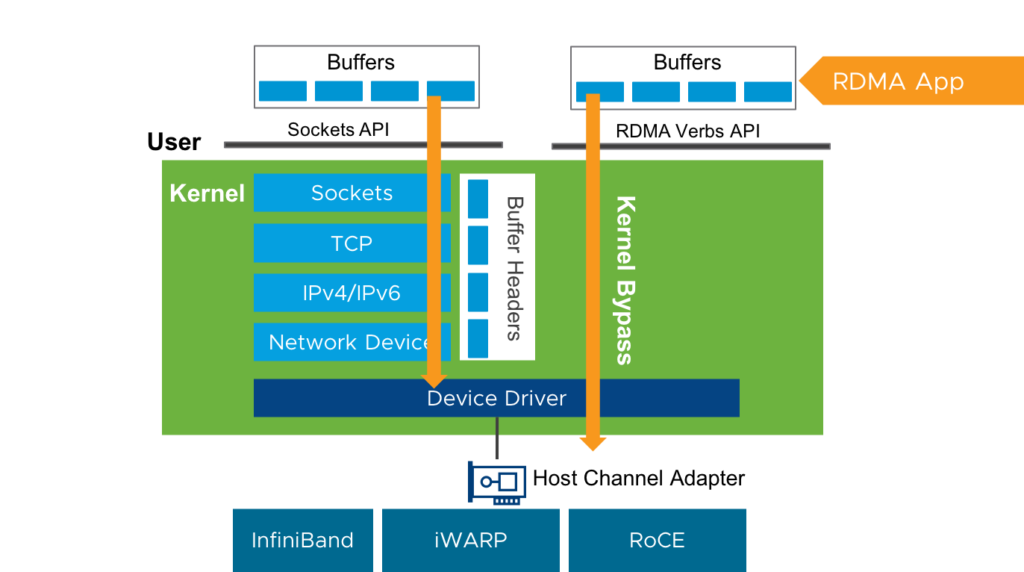
Beim Remote Direct Memory Access (RDMA) werden die Daten direkt in die Leitung gekippt. Sie umgehen Dinge wie Prozessor (CPU), Zwischenspeicher (Cache) und Betriebssystemkern einfach. Im Fall von CEPH, entfällt – je nach Zugriffsart – der Umweg über Service-Gateways, Kernelmodule, Bibliotheken und Metadatenserver. Anwendung und Storage kommunizieren also direkt miteinander. Das vermeidet lästige Kontextwechsel sowie das Zwischenspeichern der Daten. Und Workloads lassen sich zudem noch parallelisieren.
RDMA ist in der Virtual Interface Architecture, RDMA over Converged Ethernet (RoCE), InfiniBand, iSER (eine iSCSI-Erweiterung), Omni-Path und iWARP implementiert. RDMA kann auch von virtuellen Maschinen (VM) genutzt werden. Neben DirectPath I/O (auch Passthrough oder Passthru) zum Host Channel Adapter (HCA) sind RDMA-fähige Netzwerkkarten (NIC) eine Option. Um vSphere-Funktionen wie vMotion mit DirectPath I/O zu unterstützen, wird Paravirtual RDMA (PVRDMA, vRDMA) benötigt.
Hier kommt gerade auch etwas Bewegung in den Markt. Herausforderer Vcinity will das WAN zum globalen LAN machen und verspricht bei Entfernungen von mehr als 250.000 km für 10G oder bis 25.000 km sogar für 100G-Systeme verlustfreie Übertragungsraten – daten- sowie anwendungsunabhängig, ohne Komprimierung, Deduplizierung oder sonstige Datenmanipulation. Dabei setzt das Startup auf offene Standard-Protokolle für Client- und WAN-Schnittstellen und will sich transparent in bestehende Hybrid- und Multi-Cloud-Infrastrukturen einfügen.
Flash ohne Gordon
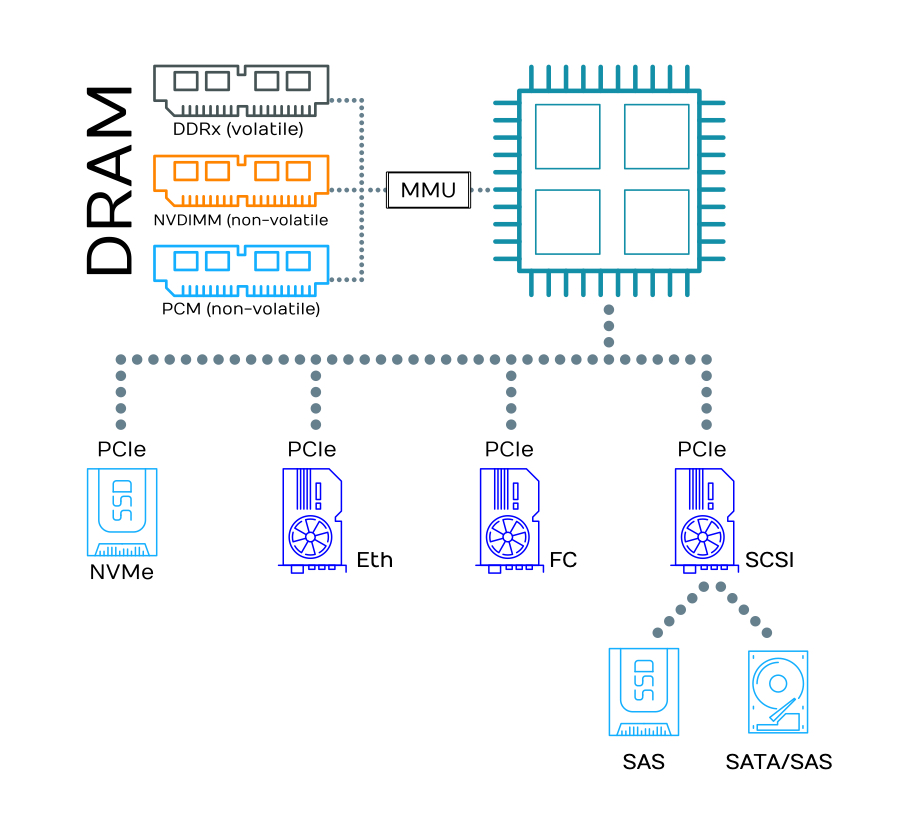
Schuld an allem sind eigentlich SSDs. Bestimmte früher die Festplatte die Geschwindigkeit, ist jetzt das Netzwerk der limitierende Faktor. Genau genommen hinken herkömmliche Storage-Protokolle hinterher. Eine Antwort darauf ist NVMe bzw. NVMe-oF (Non-Volatile Memory Express, als SAN over Fabric). NVMe nutzt PCI Express (PCIe).
Enterprise-grade Flash-Speicher kommt als Solid State Disk (SSD) in klassischer Festplattenform oder als Speicherriegel für DIMM-Steckplätze daher. SSDs sind in der Regel NAND-Speicher. DIMM-Module gibt es mit NAND- bzw. 3D NAND-Technologie (NVDIMM) oder als Phase Change Memory (PCM). Eine Sonderform gängiger SSD sind EDSFF Based Intel® Data Center SSDs (ehemals als Ruler SSD bekannt). EDSFF steht für Enterprise & Data Center SSD Form Factor. Und obwohl die EDSFF-Module von Intel® Optane heißen, sind es trotzdem nur NAND-Speicher.
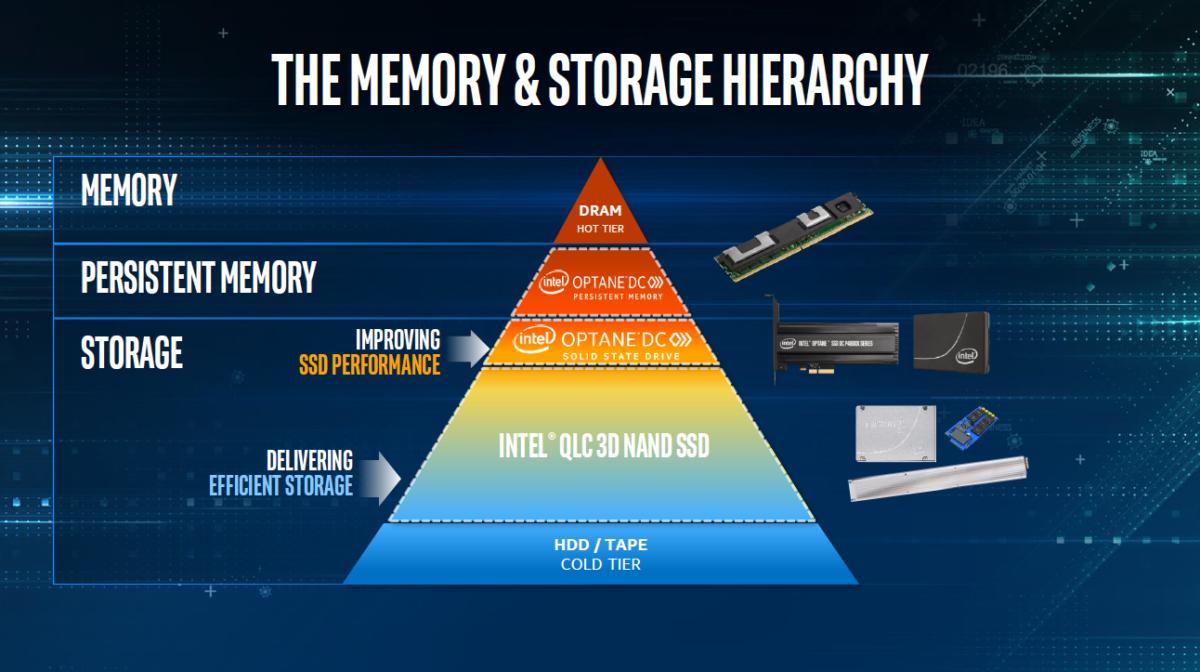
Flash-Speichermedien können vom Prozessor mehr oder weniger direkt angesprochen werden. Und nicht nur das: jeder Kern kann unabhängig mit dem Storage kommunizieren. Die zweite Möglichkeit ist es, die Daten näher an die CPU zu holen. Storage Class Memory ist schneller nichtflüchtiger Speicher im DRAM. Diese Speicherart ist als persistenter Speicher (PMEM, PRAM) oder non-volatile RAM (NVRAM) bekannt.
NVRAM wird über die Memory management Unit (MMU) der CPU angesprochen. Die Latenz bewegt sich im unteren zweistelligen Nanosekundenbereich. PCM ist dabei noch etwas schneller als NVDIMM-F (Dual In-line Memory Module mit Flash-Speicher). Das liegt daran, wie die Informationen gespeichert werden: NVDIMM basiert auf der NAND-Flash-Technologie. Um Informationen zu speichern, werden Elektronen in Floating Gates oder bei 3D-NAND auch in Charge-Traps gebunden („eingesperrt“). Ohne zu tief in die Quantenmechanik abzudriften: Eine Zustandsänderung ist entweder durch den so genannten Tunneleffekt (kompliziert!) oder die Injektion heißer Ladungsträger (hot-carrier injection) möglich. Beides beansprucht Zeit und den Speicher physisch. Letzteres erklärt auch die vergleichsweise geringe Lebensdauer eines Flash-Speichers je öfter er be- bzw. überschrieben wird. Beim Phase Change Memory ändern die Elektronen einfach ihre Richtung. Das geht drastisch schneller als das „Einsperren“ und ist auch wesentlich materialschonender. PCM hat daher auch eine höhere Lebensdauer als NAND-Flash – in Schreibvorgängen gemessen, nicht in absoluter Zeit. Die höhere Belastbarkeit sollte bei der Beschaffung einkalkuliert werden.
Die Leistungsunterschiede zwischen NAND-SSDs und PCM mit Intel® Optane™-Technologie hat ESG für Dell validiert und in einem Paper zusammengefasst.
SSDs werden mit NVMe entweder direkt über PCIe angesprochen oder im SAN per RDMA in Form von NVMe over Fabric (NVMe-oF). Latenztechnisch sind wir jetzt im Bereich ±100 Mikrosekunden.
Selbstverständlich können SSDs auch mit SAS angesprochen werden. Wir empfehlen das nicht. Lest dazu auch unseren Artikel über NVMe und SSDs. Mittlerweile gibt es NVMe auch über Fibre Channel (FC). Wir empfehlen auch das auf Dauer nicht. Ethernet-Switche sind einfach so viel günstiger und flexibler. Außerdem gibt es inzwischen sehr viel mehr Ethernet- als FC-Admins. Überhaupt sollten nur Schnittstellen und Protokolle genutzt werden, die für bestimmte Zwecke entwickelt wurden. Flashspeicher z. B. sollten immer mit NVMe direkt angesprochen werden. Alles, was für etwas verbogen (SAS-SSD) oder in etwas anderes verpackt (NVMe over FC) wird, bedeutet Performance- und Zeit-Verlust.
SAS hat noch einen weiteren Nachteil. Wie bei SATA ist die Anzahl der Kommandos in der Command Queue begrenzt. Im Gegensatz zu SATA (32 Kommandos) unterstützt SAS zwar immerhin schon 256 Kommandos. Bei NVMe sind es bis zu 64k Queues mit je 64k Kommandos. Wer es ganz genau wissen will, wird z. B. im Blog bei Simms fündig.
Mit den SCSI-Laufwerken sind wir übrigens bei Latenzen von ca. 15 Millisekunden angekommen.
Und damit schließen wir den Kreis. Jetzt müssen die Netzwerker sich was einfallen lassen und vor allem ihr Silo verlassen. Storage und Netzwerk lassen sich nicht mehr trennen.
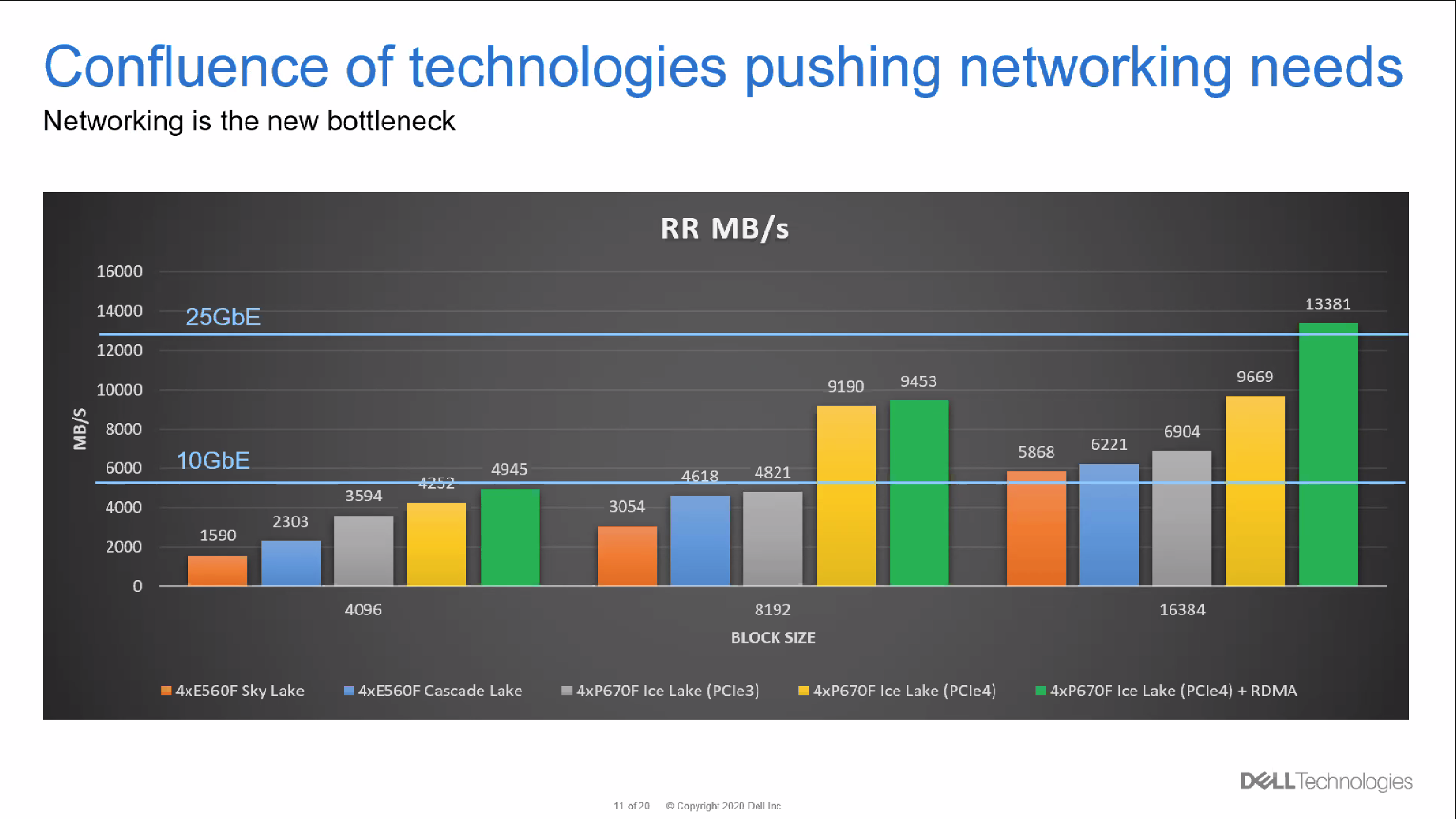
Tiers ohne fears
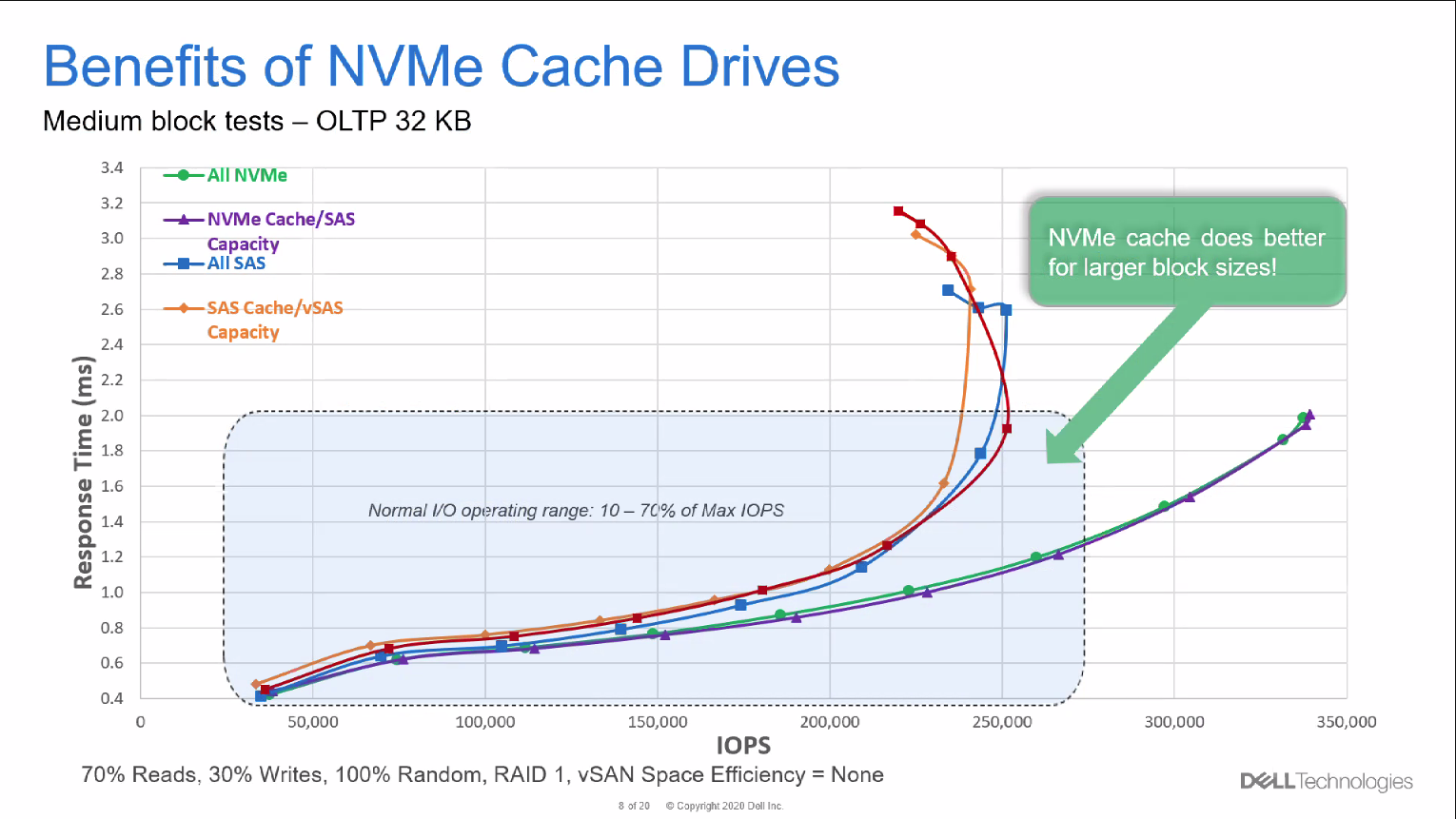
Um immer größere Datenmengen (und Dateien) verarbeiten und die Anforderungen moderner Workloads wie maschinelles Lernen (ML) oder künstliche Intelligenz (AI) erfüllen zu können, braucht es neue Ansätze. Dazu gehört SSD-Caching. Dabei werden häufig benötigte Daten temporär in NVRAM-Modulen gespeichert. Ein bisschen erinnert uns das an das Tiering in klassischen Storage-Architekturen – auch dort werden oft benutzte (heiße) Daten in Flashspeichermedien direkt auf der Storage-Node abgelegt.
Dell nutzt SSD-Caching in seinen VxRail-Nodes der nächsten Generation und setzt dabei auf die Intel® Optane™️-Technologie:
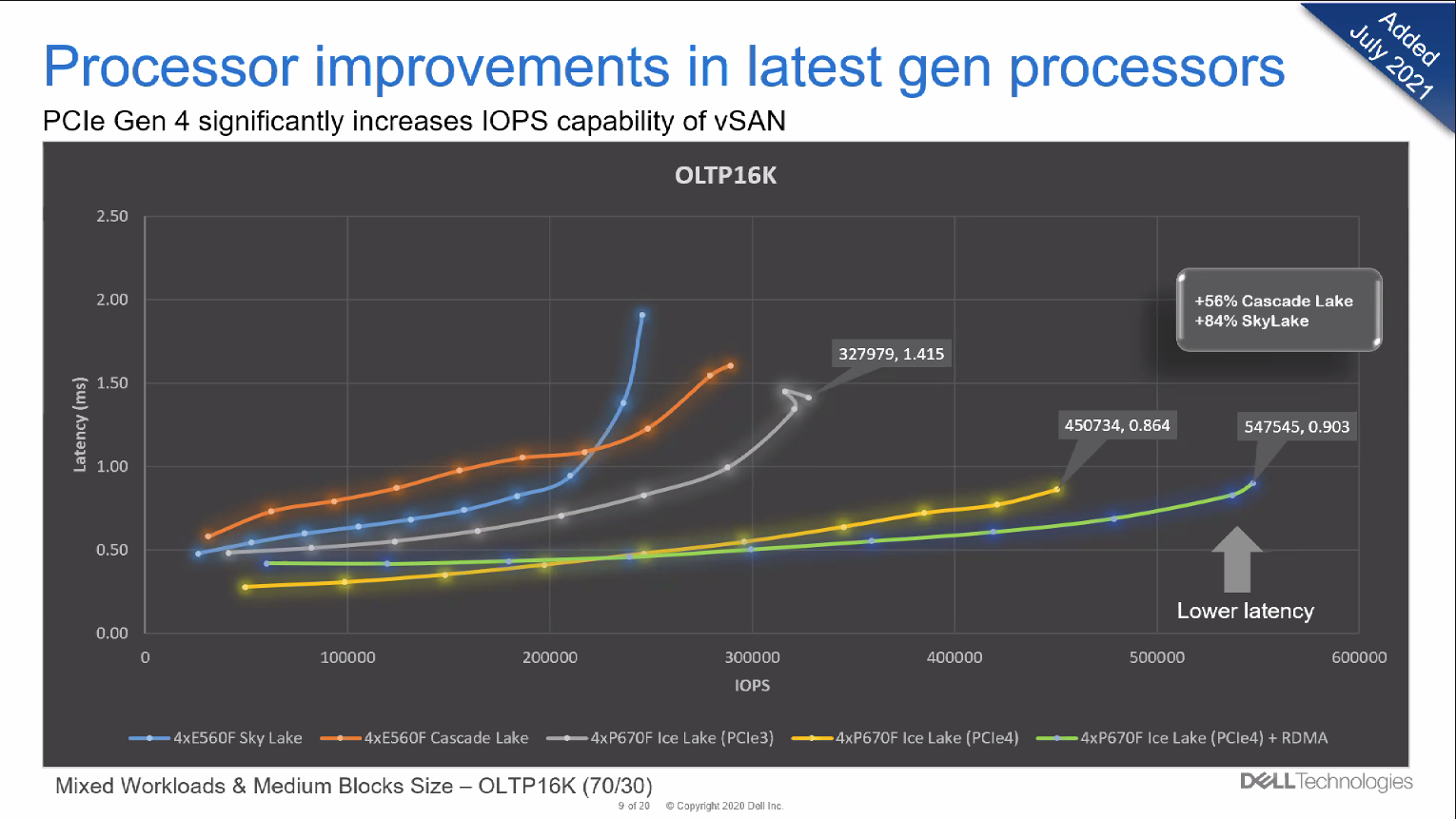
Auch die Prozessoren spielen eine Rolle beim Kampf um schnellere Laufzeiten. Die Wahl des richtigen Prozessors ist zudem nicht nur entscheidend für die Latenz. Auch die Anzahl Rechenoperationen steigt signifikant. Das hat sich Dell in einem zweiten Benchmark angeschaut.
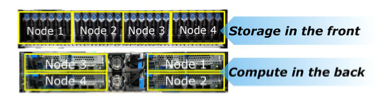
Für noch bessere Werte heben wir die Trennung zwischen Server und Storage auf. Wir konvergieren hyper. Dazu schauen wir uns VxRail etwas genauer an.
Hyper! Hyper! Hype?
Zuerst beantworten wir die Frage: Was ist Hyperkonvergenz? Die Idee hinter hyperkonvergierten Systemen ist Vereinfachung. Statt ausgewiesener Netzwerk-, Storage- oder Compute-Nodes wird von allem etwas in eine oder mehr Höheneinheiten verpackt.
Eine Software entscheidet, was davon wie genutzt werden soll. Der größte Vorteil dieser standardisierten Blöcke (building blocks) ist die Möglichkeit, Kapazitäten möglichst einfach erweitern oder schrumpfen zu können. Das betrifft sowohl die Beschaffungsseite als auch die technische Ausführung.
Es gibt einen großen Nachteil dabei: Je nachdem als was die Node genutzt wird, dümpelt der Rest ungenutzt vor sich hin und nimmt Platz weg. Bezahlen muss man auch dafür – sowohl bei der Anschaffung als auch im Betrieb. Das ließ sich nicht lange verheimlichen. Daher gibt es inzwischen Composable Disaggregated Infrastructure. Dabei hat man auch Building Blocks, jedoch wieder getrennt nach Speicher, Netzwerk und Compute. Cloud-Technologie (auch wieder Software) klebt alles passend zusammen und weiß, was wann in welcher Größe benötigt wird. Dieses Prinzip kennen wir übrigens aus der Großrechner-Architektur.
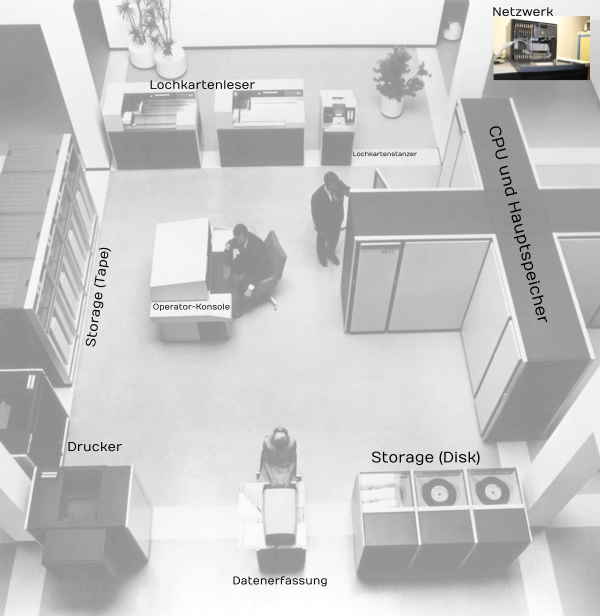
Brauchte man mehr Kapazität, wurden (nicht ganz so) einfach ein paar Module dazugestellt bzw. weitere Karten eingesteckt. In modernen Rechenzentren ist das natürlich viel agiler und komfortabler. Virtualisierung macht es möglich.
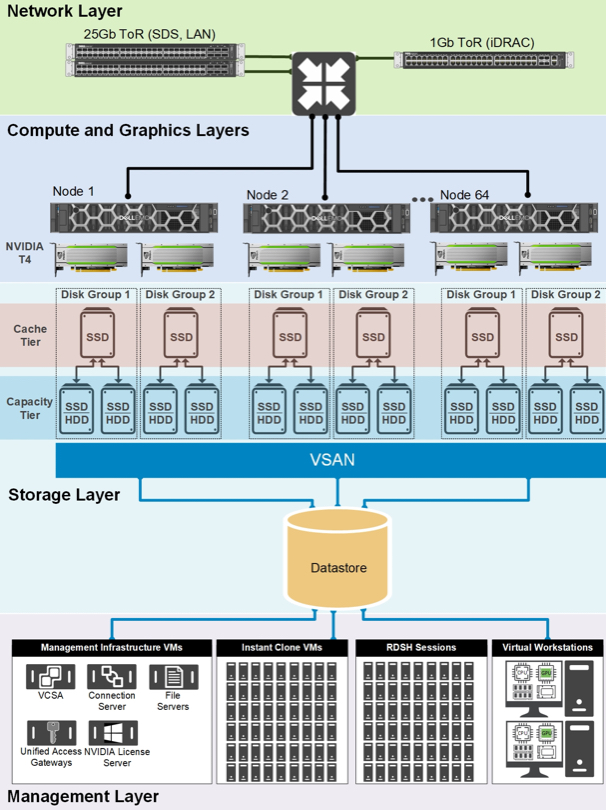
Virtualisiert wird alles, was das RZ hergibt: Netzwerke, Server und Storage. Sogar Prozessoren!
Ich will mehr … äh … weniger … mehr …
Für bestimmte Anwendungsbereiche kommen auch die besten Prozessoren schnell mal an ihre Leistungsgrenzen. Erst recht, wenn HPC-Anwendungen wie maschinelles Lernen, Strömungslehre oder 3D-Modellierung in den normalen Firmenalltag einziehen. Auch Virtualisierung wird immer anspruchsvoller. Anwender erwarten nicht erst seit Corona am remote Arbeitsplatz die gleichen Service Level wie im Büro. Virtuelle Desktops setzen daher schon länger auf die Superpower von Graphikprozessoren (GPU).
Dell weiß das auch und hat seine VxRail-Appliances mit leistungsstarken NVIDIA-GPUs ausgestattet. Mit der NVIDIA vGPU Software lassen sich physische GPU in mehrere virtuelle Einheiten aufteilen. Damit lassen sich Containern oder virtuellen Maschinen (VMs) eigene Ressourcen zuteilen.
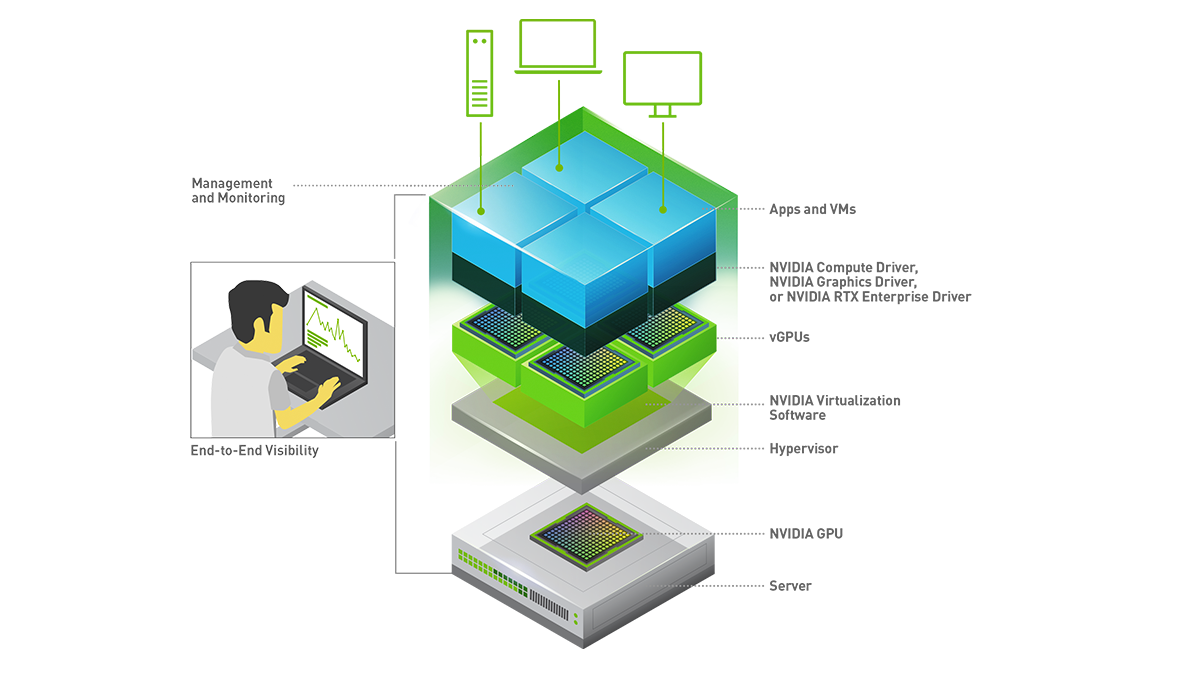
SmartNICs und spezielle Datenprozessoren (DPU) von NVIDIA sind weitere Bausteine, für die VxRail-Appliances zertifiziert sind – samt des verfügbaren Software-Zoos.

VxRail unterstützt GPUDirect RDMA, leider jedoch noch nicht NVLINK. NVLINK ist eine von NVIDIA entwickelte Multilane- Hochgeschwindigkeits-GPU-Verbindung für Multi-GPU-Systeme. Die Kommunikation ist extrem viel schneller als bei PCIe-Verbindungen, u. a. weil sie eine Mesh- statt einer Hub-Topologie nutzt. Wer das will, muss auf Dells Isilon-Lösung ausweichen oder zu Supermicro und Boston gehen. Dort gibt es NVLINK bereits in ganz gewöhnlichen Servern (ANNA-Serie).
Doch betrachten wir einmal das große Ganze. Bis hierher war alles ziemlich viel Theorie. Wie sieht das bei Dell in der freien Wildbahn aus?
Voll vernetzt
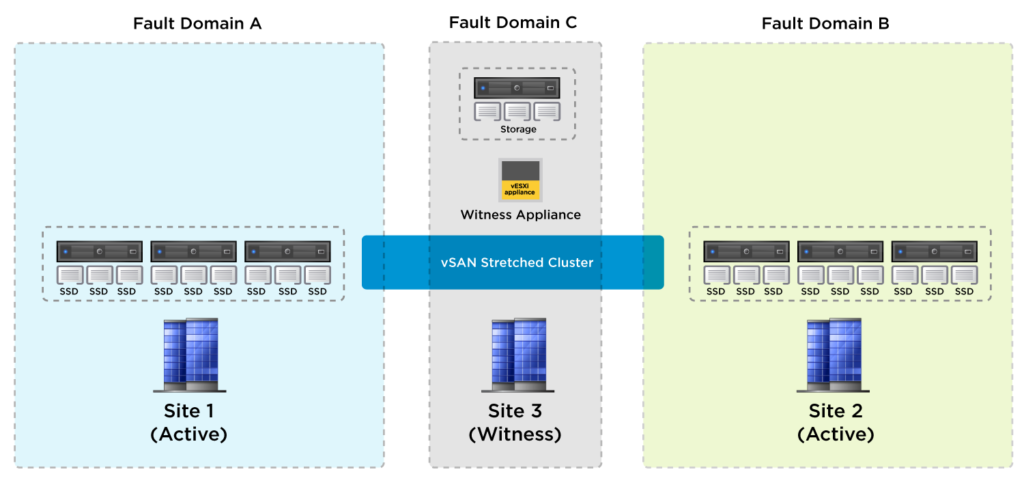
VxRail von Dell EMC wurde für und mit VMware entwickelt. Daher ist es für genau einen Zweck optimiert: VMware auf bestmögliche Weise zu unterstützen. VxRail integriert sich nahtlos in die VMware Cloud Foundation und hat natürlich alles an Bord, was das VMware-Universum zu bieten hat. Und weil es eine Ende-zu-Ende Cloud-Lösung ist, unterstützt VxRail zusätzlich zu vSAN auch vSAN HCI Mesh. Auf diese Weise lassen sich u. a. Metro-Cluster bauen. Als Anwendungsfälle nennt Dell neben dem klassischen Failover mittlerweile auch Instand-Recovery. Dazu sagen wir gleich noch etwas.
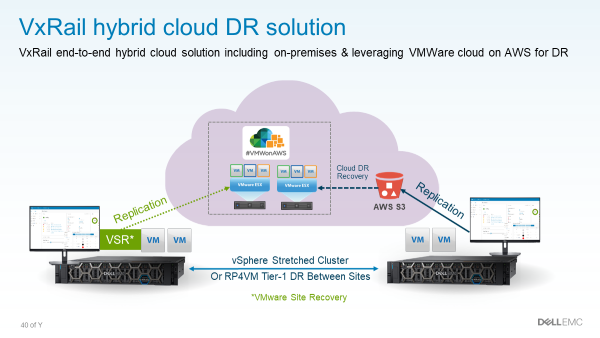
Die kleineren Boxen eigenen sich auch für den Betrieb an remote oder Branch-Standorten (ROBO).
AppsOn!
Während VxRail noch HDD und SSD gleichermaßen unterstützt, hat Dell EMC mit PowerStore eine mächtige All-Flash-Storage-Appliance entwickelt. Und obwohl Store(age) drauf steht, sieht Dell es als Infrastruktur-Plattform.
Bemerkenswert in PowerStore ist die AppsOn-Funktion. Damit können virtualisierte VMware-Workloads direkt auf dem Array ausgeführt werden. Möglich macht das ein integriertes VMware vSphere. AppsOn eignet sich hervorragend für datenlastige Anwendungen aber auch für alles, was eine niedrige Latenz erfordert. Dell nennt als Beispiele Edge- oder Analytics-Anwendungen, aber auch Monitoringsoftware und Sicherheitsprogramme wie Antivirenscanner. Im Cluster können Anwendungen nahtlos von einer Node auf eine andere geschoben werden.
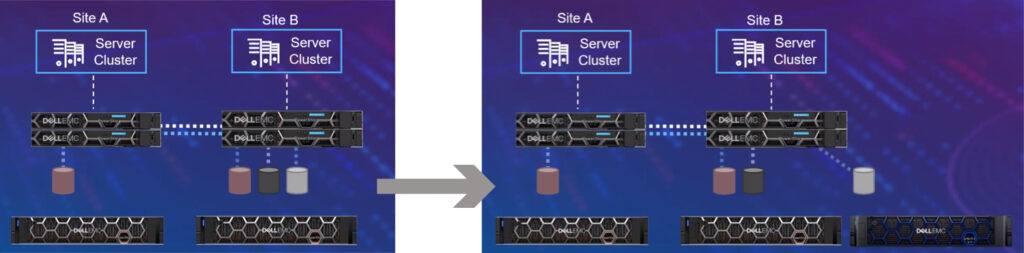
Auch PowerStore ist als Metro-Node erhältlich. Die Cluster sind active-active. Dell EMC nennt drei Modi für seine Cluster: Asynchron, Synchron und Metro-Synchron. Für letzteres verspricht der Hersteller sowohl eine RPO als auch eine RTO von Null.
Da in diesem Modus beide Cluster-Seiten nach außen als Einheit auftreten und beide wahrscheinlich in Echtzeit gespiegelt werden, glauben wir das auch. Das ist vor allem im Fall einer Ransomware-Attacke praktisch, da beide Instanzen gleichzeitig verschlüsselt werden können. Wir empfehlen auf jeden Fall noch eine seriöse Disaster-Recovery-Strategie. Und richtige Backups.
Kommuniziert wird im Cluster laut Hersteller-Website mit NVMe-FC. Unser Lieblings-Sorgenkind Fibre Channel: das NVMe macht es nicht sympathischer. NVMe over Fibre Channel setzt sich aus NVMe over Fabric (NVMe-oF) und FC-NVMe zusammen. Für den Transport wird NVMe von einem Host Bus Adapter (HBA) in Fibre-Channel-Frames gepresst. Auf der anderen Seite muss es entsprechend wieder ausgepackt werden. Das schreit förmlich nach Overhead und höherer Latenz. iSCSI wird auch unterstützt. Das macht vor dem Hintergrund Investitionsschutz Sinn. Will sich Dell allerdings wirklich als Partner der Next Generation aufstellen, sollte sich der Hersteller dringend schon jetzt auf das effizientere NVMe-oF (ohne FC!) konzentrieren und es wenigstens parallel anbieten. Das komplette technische Datenblatt findet sich auf den Herstellerseiten.
Aber wir wollen mit etwas Positivem abschließen und werfen schnell noch einen Blick auf‘s Management-GUI. Da haben wir etwas wirklich schönes entdeckt: den physical View.
Den gibt es natürlich auch in VxRail:
Fazit
Dell EMC hat sowohl mit PowerStore als auch VxRail leistungsfähige, moderne Lösungen mit ein paar wirklich innovativen Extras im Angebot. Wer schon Dell im Hause hat, kann ruhigen Gewissens (erstmal) dabei bleiben.
Wem das alles noch nicht reicht, sollte sich zusätzlich mit Computational Storage beschäftigen. Oder in einen Supercomputer investieren.
Alle Präsentationen vom Tech Field Day Presents Dell Technologies HCI & Storage (TFDxDell21) wurden aufgezeichnet und können auf den Tech-Field-Day-Seiten abgerufen werden.
Eine ausführliche Beschreibung von Storage Class Memory hat Dell auf der Homepage im Trainingscenter verlinkt.
