
Für die Sicherheit seines Unternehmens ist jeder Unternehmer selbst verantwortlich. Das gilt für die physische Sicherheit seiner Arbeitnehmer und Kunden genauso wie für die Sicherheit von Daten und natürlich auch die Sicherheit seiner Infrastruktur. Vor allem bei letztgenanntem tun Firmen sich schwer. Selbst große Konzerne scheinen so ihre Herausforderungen zu haben. Anders sind Katastrophen wie der konzernweite IT-Systemausfall bei der Lufthansa aufgrund einer durchtrennten Glasfaserleitung nicht zu erklären.
Verfügbarkeit
Hochverfügbarkeit fängt beim Strom an und hört beim Internet nicht auf. Größere Rechenzentren sollten immer jeweils zwei Hauseinführungen haben für Strom und Konnektivität. Zudem sollte für die Internetanbindung auf Carrier-Redundanz geachtet werden. Beliebt ist eine Kombination aus regionalem und globalen Anbieter. In Norddeutschland könnte das z. B. eine Kombi aus TNG 🌐 und Telekom sein.
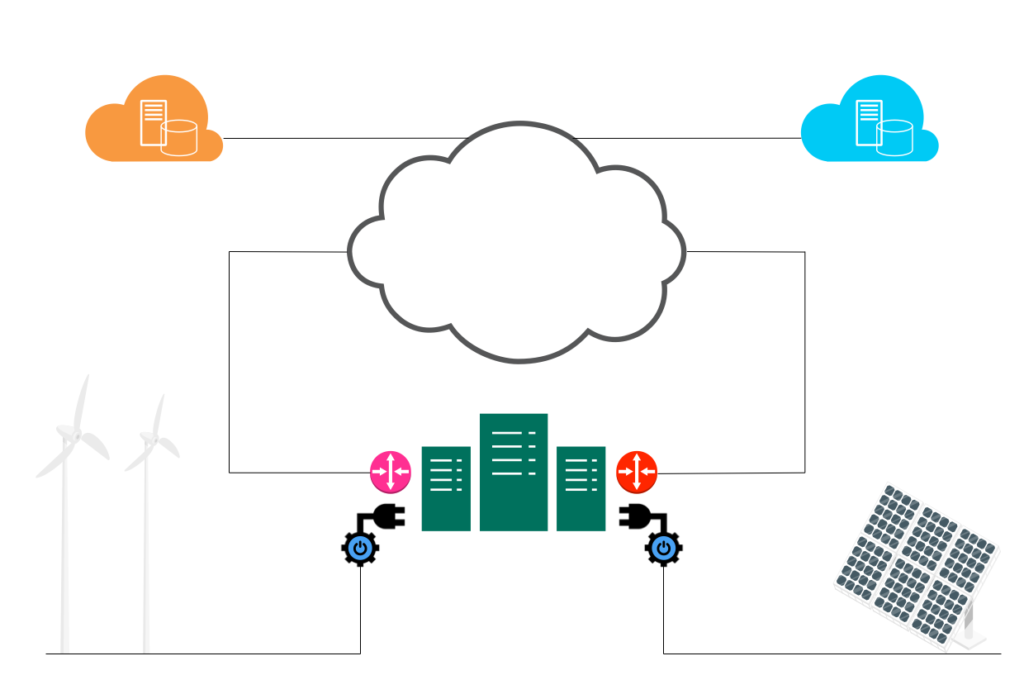
Beim Stromanbieter ist Herstellerredundanz nicht so einfach umzusetzen, da Trassen und Umspannwerke von allen genutzt werden und ein echter Single Point of Failure sind. Hier sorgen nur der gute alte Diesel für Unabhängigkeit. Die obligatorische Akku-Armee dient nur zu Überbrückung, bis der Diesel anläuft. Mit aktueller Speichertechnologie lässt sich damit immer noch kein Rechenzentrum über längere Zeit betreiben.
Gegen ein Blackout hilft Geo-Redundanz – modern als Hybrid- oder reinrassige Multicloud-Umgebung.
Heiß, warm, kalt
Auch innerhalb eines Rechenzentrums sollten alle wichtigen Systeme redundant vorhanden sein. Geringste Ausfallzeit versprechen Active-Active-Cluster. Allerdings sind die auch am aufwendigsten einzurichten und zu pflegen, was sie wieder fehleranfälliger macht. Vor allem Datenbanken neigen in HA-Verbünden gerne mal zu Inkonsistenzen. Und auch netzwerkseitig gibt es bei Active-Active-Clustern einiges zu beachten. Selbst bei aller Automatisierung und Low-Code-Ansätze muss man immer noch seine individuellen Parameter kennen. In der Linux-Welt sind HA-Cluster mit DRBD sehr beliebt. Eine Anleitung 🌐 gibt es von SUSE.
Weniger kompliziert sind Active-Passive-Cluster. Bei einem Active-Active-Cluster kann mit Loadbalancern die Arbeitslast auf beide Nodes verteilt werden. Beide sind quasi Master. Bei der Active-Passive-Aufstellung gibt es nur einen Master für die gesamte Arbeitslast. Das zweite System, der Slave, wird im Standby betrieben und nur beim Ausfall des Masters aktiviert. Die Herausforderung ist hierbei die Replikation bzw. Synchronisation der Workloads und Daten nach dem Ausfall – wenn der ursprüngliche Master wieder online ist. Meist ändern sich die Rollen nach einem Ausfall und der vormalige Master wird zum Slave. Das hält zumindest die Workloads konsistenter, da nur die Daten synchronisiert werden müssen. Außerdem vermeidet man so weitere Ausfallzeit für den Switchback.
Beide Verfahren – active/active und active/passive – sind auch als hot bzw. warm standby bekannt.
Am wenigsten kompliziert ist ein cold standby. Hierbei werden einzelne Komponenten – spare parts – oder auch ein ganzes System wie Router oder Switches kalt ins Regal gelegt. Im Falle eines Ausfalls wird das kaputte Teil ausgetauscht. Das dauert am längsten, das das System physisch bewegt, gestartet und konfiguriert werden muss. Als KMU sucht man sich hierfür einen lokalen Partner, der das übernimmt. Das ist günstiger und wahrscheinlich auch zuverlässiger.
Generell sollte in dem Zusammenhang auf Garantie und die SLAs der Hersteller geachtet werden. Anbieter wie Supermicro oder iXsystems geben standardmäßig drei Jahre Garantie. Für Service Levels gilt: Je kritischer die IT für das Kerngeschäft ist, desto höher sollte das SLA sein.
Ebenfalls nicht außer Acht lassen sollte man Redundanz im Gerät selbst. Mindestens Netzteile müssen redundant ausgelegt sein. Dabei achtet bitte immer darauf, dass Stromversorgung auch für die mögliche Last im Vollausbau gesichert ist. Die Faustregel heißt n+1. Ebenfalls bei den Platten (HDD, SSD) sollten immer ein paar in Reserve vorgehalten werden. Sophisticated Systeme wie die TrueNAS Enterprise M-Serie von iXsystems haben sogar redundante Controler eingebaut.

Keine Consumerprodukte im Rechenzentrum
Wer billig kauft, kauft dreimal. Vor allem bei Platten sind Consumer-Produkte äußerst populär. Daher an dieser Stelle eine Klarstellung: Enterprise-grade ist kein Marketinggag. Enterprise-Produkte sind für den Betrieb 7x24x365 ausgelegt und entsprechend robust. Langfristig lohnt sich also der Invest.
Die einzige Ausnahme ist Apple als Server im SMB-Umfeld. Der ist aber eh auch nicht billig.
Amazon & die 9 Elfen
Bei den physischen Vorkehrungen sollten auch Daten redundant vorgehalten werden. Als Beispiel dienen Hyperscaler wie AWS. Das Stichwort lautet Durability. Der Standard sind aktuell 11 Nines, also 99,999999999%. Das bedeutet, dass man selbst bei einer Milliarde Objekte wahrscheinlich hundert Jahre lang kein einziges verlieren würde. Erreicht wird das durch Mehrfach-Redundanz.
Vertrauen ist gut. Kontrolle ist besser.
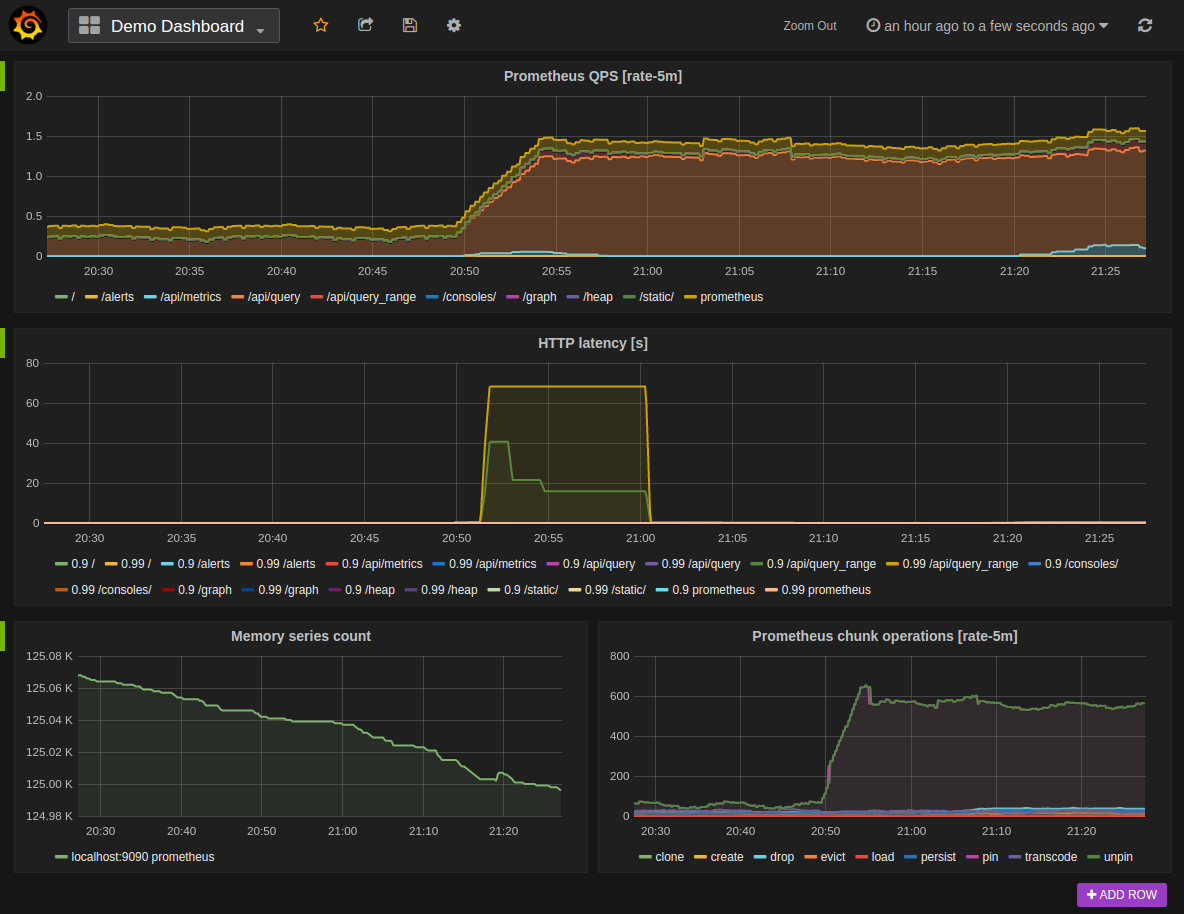
Zur Ausfallsicherheit gehört auch immer ein Monitoring – am besten mit predictive Analysis. Prometheus 🌐 z. B. kann das recht gut und ist zudem auf Basis von Open Source. Mit der Grafana-Visualisierung lassen sich Flaschenhälse und Ausfallrisiken schnell erfassen.
Failover. Fail!
Damit im Disaster-Fall auch alles wie gewünscht funktioniert, müssen Failover-Szenarien regelmässig getestet werden. Ein Praxisbericht 🌐 von Kristian Köhntopp zeigt, was alles schief gehen kann trotz ausgedehnter Redundanzen – und bester Absichten.
Pro-Tipp: Notfallpläne immer auch ausdrucken und an prominenter, leicht zugänglicher Stelle deponieren! Wenn das Rechenzentrum stirbt, sind auch die darin gespeicherten Daten in der Regel nicht verfügbar.
