
Dieser Artikel basiert auf einem Gastbeitrag von Abhijit Dey, Chief Product Officer bei DataCore.
Daten sind allgegenwärtig und eine mächtigen Kraft in der digitalen Welt. Aus zahlreichen Quellen generiert sind Daten ständig in Bewegung on premises im Core oder am Edge sowie in der Cloud. Geschäftsprozesse, Anwendungen und die Daten selbst bestimmen, wo und wie Informationen gespeichert und verarbeitet werden sollten. Die Schwerkraft der Daten wird zu einem Schlüsselfaktor, der sowohl den Ort der Datenverarbeitung als auch die Speicheranforderungen erheblich beeinflusst. Neue Technologie wie künstliche Intelligenz und damit verbundene Arbeitsabläufe erfordern eine neue Agilität von Speichern.
Eine Antwort auf diese modernen Herausforderungen ist das Konzept der schwimmenden Daten. Speicher müssen in hohem Maße komponierbar sein in Design und Betrieb. Der Erfolg vieler Unternehmen im Jahr 2024 wird von der Fähigkeit des Speichers abhängen, sich nahtlos an verschiedene Standorte und Technologien anzupassen und dabei Reaktionsfähigkeit, Flexibilität und Wirtschaftlichkeit zu gewährleisten. Vor diesem Hintergrund wagt DataCore drei Prognosen für die Entwicklung der Datenspeicherung im Jahr 2024 und stellt eine Zukunft mit strategisch ausgerichteten Speicherplattformen vor, die den veränderten Anforderungen des Datenökosystems gerecht werden.
SSDs und Composable Storage
Seit Jahren findet im Speichersektor ein allmählicher Wechsel von traditionellen HDDs zu SSDs statt. 2024 wird der Wendepunkt erreicht, an dem die neu installierte SSD- und Flash-Kapazität zum ersten Mal die HDD-Kapazität übersteigt. Da SSDs im Vergleich zu ihren Pendants mit rotierenden Spindeln ein schnelleres Kapazitätswachstum aufweisen, sind Organisationen mit der komplexen Aufgabe konfrontiert, SSDs zu integrieren, die Datenmigration zu optimieren und SSDs und HDDs in gemischten Speicherkonfigurationen harmonisch zu betreiben.
Der Aufstieg der SSDs ist aber nicht nur eine Weiterentwicklung der Speicherhardware, sondern auch ein Vorläufer für eine tiefgreifende Veränderung der Speicherinfrastruktur selbst. Composable Storage basierend auf den Prinzipien der Composable Infrastructure ermöglicht es Unternehmen, neue Technologien nahtlos und ohne Unterbrechung zu integrieren. Dynamisches Reagieren und Rekonfiguration während des laufenden Betriebs erfüllen individuelle Anforderungen und gewährleisten andauernde Flexibilität, Widerstandsfähigkeit und Nachhaltigkeit. Die Kompositionsfähigkeit hilft zudem bei der Vermeidung von Silos und und optimiert die Nutzung vorhandener Ressourcen.
Angesichts des rasanten technologischen Wandels in den Unternehmen stellt die Möglichkeit der Wiederverwendung von Ressourcen sicher, dass sie sich anpassen können, ohne bei Null anfangen zu müssen, und ebnet so den Weg für flexiblere und reaktionsschnellere Abläufe. Damit steigt auch die Nachfrage nach Lösungen zur Integration und Vereinfachung des Betriebs heterogener (gemischter) Speicherumgebungen.
Der revolutionäre Sprung von Object Storage mit Containerisierung
Der Objektspeicher, der traditionell im Kern und in der Cloud eingesetzt wird, profitiert von der neuen Datendynamik. Immer größere und vielfältigere Datenmengen verändern die bisher eher konventionellen Architekturen von Objektspeichern. Die Schwerkraft der Daten zieht Anwendungen und Dienste näher zusammen. Dies erfordert Speichersysteme, die in der Nähe solch datenintensiver Anwendungen eingesetzt werden können. Umgekehrt erfordert das Edge Computing eine Speicherinfrastruktur, bei der die Daten nicht nur in einem zentralen Repository gesammelt, sondern dezentral in der Nähe ihres Ursprungs an weit entfernten und verteilten Standorten verarbeitet werden. Containerisierung von Objektspeichern (z. B. mit Kubernetes) in einem kompakten Formfaktor stellt Dienste auf einzelnen Servern oder Geräten an diesen verteilten Standorten bereit. Das erlaubt Unternehmen schneller auf Erkenntnisse reagieren, verringert Latenzzeiten und erhöht die betriebliche Effizienz.
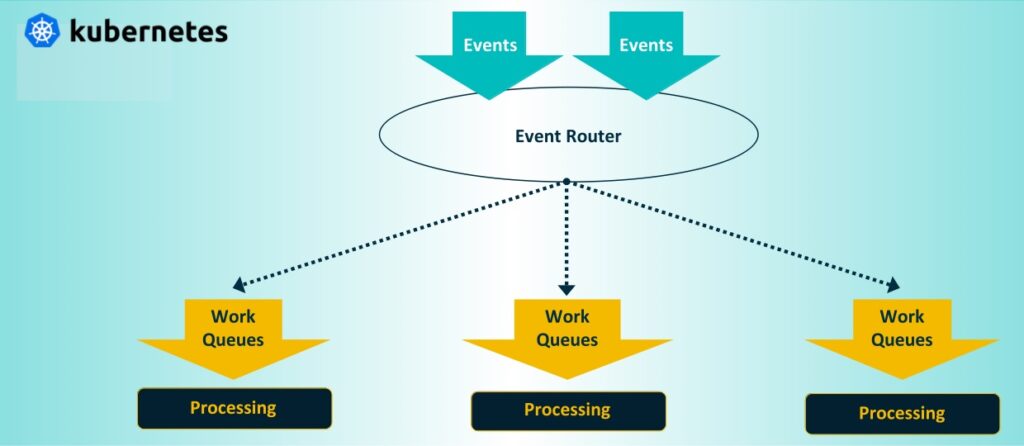
Die containerisierte Objektspeicherinfrastruktur entwickelt sich weiter, um den sich ständig ändernden Datenanforderungen der modernen Welt gerecht zu werden. Objektspeicherdienste werden zunehmend containerisiert für ereignisgesteuerte Datenverarbeitung und Echtzeiteinblicke in Geschäftsabläufe.
Umfassendere Datendienste in Unternehmensqualität mit Container-Native Storage
Im Jahr 2024 wird die zunehmende Verbreitung von Containern die Art und Weise, wie Unternehmen Anwendungen einsetzen und verwalten, grundlegend verändern. Dieser entscheidende Wandel markiert eine wichtige Entwicklung in den Technologiestrategien der Unternehmen und läutet eine Ära der verbesserten Agilität, Skalierbarkeit und Effizienz ein.
Container für eine Vielzahl von Anwendungen einsetzen, z. B. für das Training von KI/ML-Modellen und verschiedene Datenbanksysteme fordern hochverfügbare, zuverlässige Speicherlösungen. Die spezifischen Anforderungen von latenzempfindlichen Stateful-Workloads führen zu einer Verlagerung hin zu Container-nativen Speicherlösungen, die für eine nahtlose Integration in Kubernetes-Ökosysteme konzipiert sind. Herkömmliche Speicherlösungen sind traditionell nicht containernativ. Sie stehen vor großen Herausforderungen, wenn sie sich an die sich schnell ändernden Speicheranforderungen von Microservices anpassen sollen. Dies unterstreicht eine breitere Branchenbewegung hin zu ausgereifteren und fortschrittlicheren Datendiensten in containerisierten Umgebungen.
Fazit
An der Schwelle zum Jahr 2024 steht die IT-Landschaft vor einem bahnbrechenden Wandel. Die steigende Verbreitung von SSDs und der zunehmende Fokus auf Nachhaltigkeit fördern den Bedarf an Composable Storage. Objektspeicher entwickelt sich weiter. Darüber hinaus wächst der Bedarf an Container-nativem Speicher, damit moderne, auf Microservices basierende Anwendungen nahtlos in verschiedenen Umgebungen arbeiten können.
Um in der datenzentrierten Welt von morgen wettbewerbsfähig und relevant zu bleiben, müssen Infrastrukturverantwortliche bereit sein, Innovationen anzunehmen und zu integrieren. DataCore unterstützt Unternehmen mit seiner Plattform beim Technologiewandel. Zu den Neuerungen bei seinen Speicherangeboten SANsymphony und Swarm gehören u. a. Adaptive Data Placement als ein elementarer Meilenstein in der Entwicklung des Blockspeichers und Containerisierung für die Erweiterung von Objektspeichern in den Edge-Bereich.
Mit Adaptive Data Placement werden kritische Zuweisungsprobleme von Speicher adressiert, mit denen IT-Teams seit vielen Jahren konfrontiert sind: 10% der Daten einer Organisation sorgen typischerweise für 90% des gesamten I/O-Verkehrs. Welche Daten diese 10% ausmachen ändert sich ständig, da die Relevanz bzw. Zugriffshäufigkeit auf die Daten stetig wechseln. Die Herausforderung besteht darin, die verbleibenden 90%, auf die wenig oder gar nicht zugegriffen wird, davon abzuhalten, teure und hochleistungsfähige Speicherressourcen zu belegen. IT-Administratoren müssen sich somit oftmals zwischen einer Leistungs- oder einer Kapazitätsoptimierung entscheiden, die in der Regel auf Kosten des jeweils anderen geht.
SANsymphony’s Adaptive Data Placement löst diesen Zielkonflikt, indem es die Vorzüge von automatischem Daten-Tiering mit denen von Inline De-Duplizierung und Komprimierung für ein und dasselbe Speichervolumen kombiniert. So werden schnelle Antwortzeiten für Anwendungen sichergestellt, wenn sie auf ihre heißen Daten zugreifen, während gleichzeitig die Kosten für die Speicherung ihrer kalten Daten gesenkt werden.
Alexander Best, Senior Director of Product Management bei DataCore
Mit Adaptive Data Placement können heiße Datenblöcke in nicht komprimierten Tier-Klassen abgelegt werden während kalte Datenblöcke kapazitätsoptimiert auf unteren Tier-Klassen platziert werden.
Dies ist eine Weiterführung des Tiering-Konzepts und bringt Auto-Tiering auf ein ganz neues Level.
Christian Baldauf, IT-Consultant bei der MightyCare Solutions GmbH
Zahlreiche weitere Verbesserungen wie komprimierte Snapshots und Rollbacks und erweiterte Verwaltungseinstellungen gehören ebenfalls zur neuen Version von SANsymphony.
Seiner Objektspeicherplattform Swarm hat DataCore einen einfacheren, flexibleren und agileren Ansatz mit einem Ein-Server Betriebsmodell hinzugefügt. Diese neue Option ist speziell auf die besonderen Anforderungen von Edge-Workloads zugeschnitten. Swarm wurde dazu vollständig containerisiert und für den Betrieb auf einem einzelnen Server mit Kubernetes optimiert. Das ermöglicht kompakte Konfigurationen, die sich ideal für Edge- und Zweigstellen-Installationen eignen. Die hochwertigen Datendienste und die Content-Management Funktionen von Swarm erfüllen so effektiv die wachsenden Speicheranforderungen und ereignisgesteuerte Datenverarbeitung im Edge-Bereich.
Durch die zusätzliche Option einer agilen Einzel-Server-Lösung vereinfachen wir nicht nur die Infrastruktur, sondern bringen auch robuste und hochwertige Datendienste des Objektspeichers direkt zum Edge. Innovationen wie diese unterstreichen unser Engagement, uns mit der sich schnell verändernden Datenlandschaft weiterzuentwickeln. Dadurch stellen wir sicher, dass unsere Kunden ihre Daten speichern, schützen und verarbeiten können, unabhängig davon, wo diese generiert werden.
TW Cook, Vice President Product Development bei DataCore Software.
Swarm 16 umfasst nach gleichartigen gemeinsam erarbeiteten Verifizierungen von Veeam und Commvault die Integration mit Veritas NetBackup über S3-Object-Locking für eine verbesserte Cyberabwehr und zuverlässige Ransomware-Resilienz.
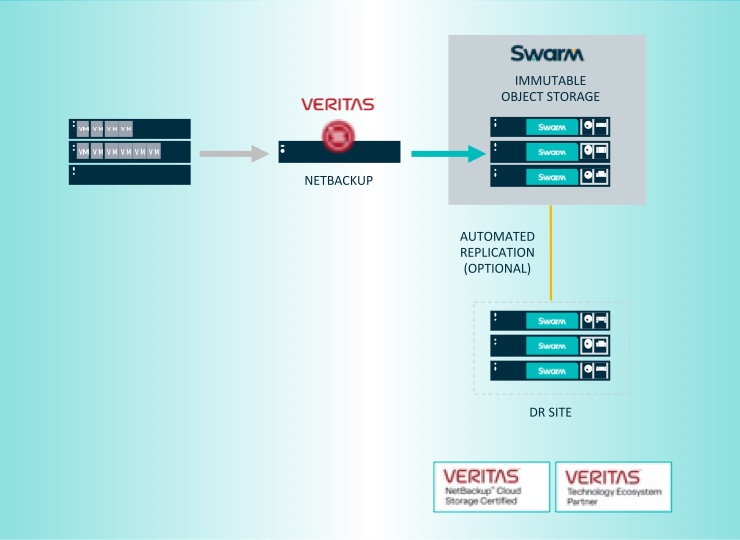
Auf der weiteren Roadmap für 2024 stehen ganz oben Entwicklungen von Storage für VMware und NVMe-over-Fabrics.

