2017 veränderte ScaleFlux mit Computational Storage die Art, wie große Datenmengen verarbeitet werden. Mittlerweile bietet der Pionier mit seiner 3000er Serie SSDs der nächsten Generation. Doch wer ist ScaleFlux überhaupt und was ist Computational Storage?
Was ist Computational Storage?
Computational Storage ist eine auf Performance optimierte Form von SSDs. Mit der Technologie wird Rechenleistung näher an die Daten gebracht. Nützlich ist das vor allem überall dort, wo riesige Datenmengen anfallen und verarbeitet werden müssen. Oder wie es die SNIA ausdrückt: „Anwendungen, bei denen die Nachfrage nach der Verarbeitung ständig wachsender Storage-Workloads die traditionellen Compute-Server-Architekturen übersteigt“.
Vor allem Datenbanken profitieren von Computational Storage. Dort fallen Daten oft schneller an, als sie gespeichert werden können oder werden schneller benötigt, als die Lesegeschwindigkeit des Storage es zulässt.
Die Geschwindigkeit einer HDD ist physisch begrenzt. Bei SSDs ist die große Herausforderung das Housekeeping. Um HDDs schneller zu machen, werden sie gern mit einem Flash-Chip ausgestattet. Damit lassen sich die Daten cachen. Das hilft vor allem bei Schreibzugriffen.
Ein erster Ansatz, Daten näher an die CPU zu bringen, waren Storage Tiers:
- Caching, PMEM und SSD für heiße – oft benötigte – Daten mit schnellen, kurzen Wegen zur CPU
- HDD mit viel Kapazität für warme – seltener benötigte – Daten, oft auch an günstigeren Standorten
- Tape für Archive
In bestimmten Bereichen war aber auch das nicht mehr ausreichend. Zwar konnte man mit ein paar Tricks (NVMe-oF, Infiniband) die Latenz im Netzwerk noch etwas minimieren. Aber das eigentliche Problem der SSDs bekam man damit nicht in den Griff. Zuviel Leistung und Speed musste an Dinge wie Indexierung, Compression oder Garbage Collection verschwendet werden. Darunter leiden besonders Key Value Stores wie REDIS oder Aerospike, aber auch verteilte Rechencluster wie Hadoop.

Mit RocksDB wollte man dem Thema softwareseitig zu Leibe rücken. Die Herausforderung hierbei ist die Hardware. Entweder muß es mit General-Purpose-Devices und -Komponenten klar kommen oder es wird auf eine DPU gesetzt – das ist aber auch nur semi-optimal. Selbst wenn SW- und HW-Entwickler eng miteinander arbeiten, bleibt immer ein Gap.
Computational Storage sind für bestimmte Einsatzzwecke optimierte HW- und SW-Stacks aus derselben Schmiede. Arbeitete man zu Beginn noch mit FPGAs sind fast alle Angebote mittlerweile ASIC-basiert.
Der erste Anbieter von kommerziell erfolgreichem Computational Storage war ScaleFlux, damals noch ein eher unbekanntes Startup aus Israel.
Mittlerweile gibt es unterschiedliche Ansätze und Namen dafür. Doch egal, ob etwas Extreme Data Processor (XDP), Hardware RAID (GRAID), Reconfigurable Dataflow Unit (RDU) oder Functional Storage Device (FSD) heißt – alle haben das gleiche Ziel. Jedes von ihnen möchte in einem speziellen Anwendungsfall die Performance erhöhen und die Latenzen minimieren. Und so wie RDU auf NLP spezialisiert ist oder GRAID auf SATA-SSDs sind ScaleFlux Experten für Datenbanken und Hadoop.
Computational Storage gibt es entweder als Add-in Card (AIC) mit PCIe- oder als SSD mit U.2-Schnittstelle.

Die Secret Sauce ist dabei eine spezielle Storage Engine, die Speicherberechnungen transparent für System, Anwendung und Anwender direkt im Datenpfad durchführen kann. Das entlastet die CPU und umgeht den Storage-Stack im Betriebssystem. Indem Storage Engine und Hardware gemeinsam entwickelt werden, können beide optimal aufeinander abgestimmt werden.
Wer ist ScaleFlux und was macht es?
ScaleFlux wurde 2014 gegründet und ist der Pionier bei der Bereitstellung von Computational Storage in großem Maßstab. 2017 lieferte das Unternehmen branchenweit die ersten Computational-Storage-Produkte aus. Als System-on-a-Chip (SoC) verbinden ScaleFlux-Lösungen Speicher, Arbeitsspeicher und Rechenleistung miteinander. Spezialisierte ASICs und eine Computational Storage Engine (CSE) bringen intelligente Speicherverarbeitungsfunktionen in NVMe SSDs.

Auf dem Open Compute Project Global Summit 2022 stellte ScaleFlux die SFX 3000-Serie vor. Neu sind die Fähigkeit zur Verschlüsselung und programmierbare Funktionen.
Mit dem auf der Arm®-Technologie basierenden Computational Storage von ScaleFlux lassen sich unnötige Datenbewegungen minimieren und die Speicherplatzdichte erhöhen. Ein Speicherlebenszyklus-Management verlängert den Lebenszyklus einer SSD. Eine höhere Rechendichte innerhalb fester Energiebudgets verbessert die Effizienz im Rechenzentrum.
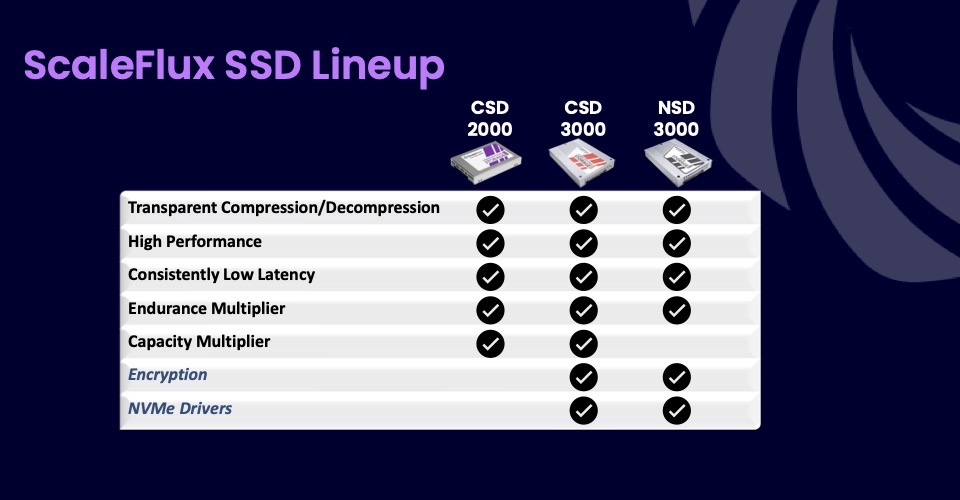
Das Line-up
Diese neue Produktlinie umfasst die CSD 3000 Serie NVMe Computational Storage Drives, die NSD 3000 Serie NVMe SSDs und den SFX 3000 Storage Processing SoC.

Computational Storage CSD 3000 senkt die Kosten für die Datenspeicherung und erhöht die Performance von Anwendungen.
Mit den NVMe-SSDs NSD 3000 lassen sich Ausdauer und Leistung bei zufälligen Schreibvorgängen und gemischten Lese-/Schreibvorgängen verdoppeln.
Der Storage-Prozessor SFX 3000 ist ein SoC incl. Firmware aus dem Hause ScaleFlux. Damit können Laufwerks- und Hardwareanbietern ihre eigenen SSDs und Beschleunigerkarten entwickeln.
Jedes Produkt wird von ScaleFlux ausgiebig getestet. Das Unternehmen veröffentlich in seinem Blog regelmässig Benchmarks wie dieses Beispiel mit PostgreSQL.
Testaufbauten im ScaleFlux-Lab



ScaleFlux-Produkte können standalone gekauft werden oder bereits fertig integriert in z. B. einer hyperkonvergenten Plattform. Ein Integrationspartner von ScaleFlux ist Scale Computing. Produkte und schlüsselfertige Lösungen sind in Deutschland bei Boston Server & Storage Solutions erhältlich.

Die Hauptmärkte von ScaleFlux sind derzeit Amerika und Asien. Mit seinem neuen Partnerprogramm hofft das Unternehmen, auch in Europa populärer zu werden.
Computational Storage verschafft Unternehmen einen Wettbewerbsvorteil, indem er die Komplexität reduziert und die Wertschöpfung aus Daten beschleunigt.
Hao Zhong, Co-Founder und CEO von ScaleFlux
Worauf musst du bei der Auswahl achten?
Ganz entscheidend ist natürlich, dass die im Unternehmen eingesetzte Software prinzipiell Computational Storage verwenden kann. Oracle-Datenbanken profitieren bestenfalls von der transparenten Komprimierung. Dann ist der konkrete Anwendungsfall zu betrachten. Was sind die konkreten Workloads (Datenbanken, AI/ML, etc)? Welche Datenbanken sind im Einsatz? Welche Art von Daten werden verarbeitet (Files, Objects, Blocks, Text, Sprache, Raw Media, …)? Was soll erreicht werden? Soll der Storage schneller werden oder mehr Kapazität bieten? Ebenfalls wichtig ist die Frage, welcher Formfaktor es sein soll (U.2, AIC)? Werden Protokolle wie NVMe im Netzwerk unterstützt? Verfügen die Server über passende U.2-Schnittstellen? Nicht unwichtig ist auch die Frage, welche Frameworks oder Cloudfunktionen unterstützt werden. Werden z. B. viele Daten bei AWS verarbeitet, sind AWS Lambda und S3 Event Notifications sinnvoll.
Wir trafen JB Baker, Executive bei ScaleFlux im Rahmen einer IT Press Tour 2022 in Palo Alto.

