
Diese Woche – 09.-11. März 2022 – ist Storage Field Day 23. Dort treffen sich die Sponsoren der Veranstaltung mit Storage-Analysten und -Influencern, und sprechen vor laufender Kamera über ihre Produkte und Technologien. Verfolgen lässt sich das alles per Live-Stream auf der Website oder bei Tech Field Day auf LinkedIn. Wurden die Field Days im letzten Jahr noch zu 100% als virtuelle Veranstaltung durchgeführt, ist das Format zwischenzeitlich hybrid: Ein Teil der eingeladenen Delegates erleben die Präsentationen gemeinsam in einem Hotel im Silicon Valley, ein anderer Teil nimmt wie gehabt per Zoom-Session an den Präsentationen teil. Mitdiskutieren können alle gleichermaßen. Der Verfasser dieser Zeilen ist zum SFD23 als Delegate geladen, blieb aber sicherheitshalber zuhause im vertrauten Home Office in Südostbayern.
Die insgesamt acht Sponsoren decken ein breites Spektrum an Storage-Lösungen ab. Schließlich sind die Zeiten längst vorbei, wo Storage einfach nur „ein Chassis oder Rack voll mit Festplatten und SCSI-Anschluss“ bedeutete. Heute passiert viel als Object Storage in der Cloud (aka S3) und mit Kubernetes. Es gibt Software zur Schadensbegrenzung und für Gegenmaßnahmen bei Ransomware-Angriffen. Um weiterem Datenwachstum Herr zu werden, werden Daten automatisch mit Metadaten angereichert, um sie so leichter wieder zu finden oder automatisiert weiter verarbeiten zu können. Weil Daten das neue Gold sind, gibt es auch Storage-Produkte, die Daten auf dem Weg von A nach B gezielt und beabsichtigt manipulieren können. Weil man z. B. mit Komprimierung oder Deduplizierung Bandbreite (und Plattenplatz) sparen kann, oder weil man mit verteiltem Erasure Coding die Zuverlässigkeit des Gesamtsystems erhöhen möchte. Im Vorfeld haben sich einige der Delegates mit dem Veranstalter Gestalt IT in einer Episode On-Premise IT ausgetauscht zu Veränderungen der modernen Storage-Welt.
Dieser Artikel ist Teil 1 einer als 3-teiligen Artikelreihe geplanten Serie zum Storage Field Day 23. Die anderen beiden Teile sind am Ende des Artikels verlinkt.
Disaggregated Composable Infrastructure: Fungible, Inc
Herzstück aller Lösungen von Fungible ist eine selbst entwickelte DPU (Data Processing Unit). Das ist ein Chip, den man sich wie ein Co-Prozessor vorstellen kann, der aber im Datenpfad eines Systems sitzt, also am PCIe-Bus. Die DPU nimmt Daten vom Bus entgegen, kann darauf Operationen ausführen (komprimieren, deduplizieren, Prüfsummen errechnen, verteiltes Erasure Coding im Netzwerk u. a.) und die veränderten Daten dann weiter geben. Fungible-DPUs vermitteln aktuell zwischen PCIe und Ethernet und benutzen dazu NVMe over TCP. Weil das alles sehr nahe an der Hardware passiert, und weil die DPU auf diese Art Datenfluss optimiert ist, geht das alles sehr schnell. Fungible stellt ausgewählten Kunden ein SDK zur Verfügung, um einer DPU kundenspezifische Funktionen zu verpassen. Die Programmierung erfolgt in C. Es ist zu erwarten, dass der Funktionsumfang über die nächsten Monate deutlich zunimmt.

Neben PCIe-Steckkarten mit Fungible S1- oder F1-DPUs gibt es auch ein dazu passendes Storage-System FS1600 mit maximal 24 NVMe-SSDs.
Mit PCIe 5.0 und PCI 6.0 wird der PCIe-Bus dann auch so schnell, dass sich mit Hilfe solcher DPUs die einzelnen Komponenten eines Computers (CPU, Memory, persistenter Datenspeicher) räumlich innerhalb eines Racks verteilen lassen. Als Composable Infrastructure wird es dann möglich werden, Hardware passend zur erforderlichen Leistung für eine Aufgabe dynamisch aus einem Ressourcenpool zusammen zu schalten und nach Bearbeitung der Aufgabe die Komponenten dem Ressourcenpool wieder zur Verfügung zu stellen.
Der Technology Scout sieht Disaggregated Infrastructure bzw. Composable Infrastructure als einen wichtigen Trend der nächsten Jahre, der die Art, wie Rechenzentren Compute- und Storage-Ressourcen benutzen, deutlich verändern wird. Vermutlich ist es aber auch nur eine Frage der Zeit, bis die dazu notwendigen DPU-Funktionen von den großen CPU-Schmieden adaptiert werden und in CPUs einziehen. CXL als Protokoll wurde für genau solche Funktionalität erdacht und spezifiziert. Spezielle DPUs sind dann für Composable Infrastructure nicht mehr erforderlich. Um Daten direkt im Datenpfad zu manipulieren, wird es weiterhin DPUs geben. Das Angebot wird größer und spezialisierter werden, insgesamt werden DPUs aber ein Nischenmarkt bleiben.
Alle Präsentationen von Fungible auf dem Storage Field Day 23 sind nachzusehen auf der Webseite des Tech Field Day.
Keine Angst vor Ransomware: RackTop Systems
Vor Ransomware kann man sich kaum schützen, irgendwann fängt man sich sowas ein. Als Unternehmens-IT kann man aber sehr wohl Vorkehrungen treffen, um einen Angriff schnell abwehren und den Normalzustand ebenso schnell wieder herstellen zu können. Es braucht dazu mindestens ein zuverlässiges Backup mit Air-Gap und einen eingeübten (!) Restore-Prozess. RackTop Systems schickt sich an, per Appliance viel schneller reagieren zu können, und damit auch den potentiellen Schaden deutlich kleiner werden zu lassen. Die Unternehmensgründer haben NSA-Vergangenheit. Vermutlich verstehen sie also einiges von Datenschutz und Datensicherheit.
Das Grundprinzip von BrickStor SP ist Verhaltensanalyse auf Daten, andere können das auch. Häufig hat man eine solche Analyse im Bereich des Netzwerk-Schutzes, eher selten auf Daten. Daten werden zum einen manuell kategorisiert (z. B. „Archiv“) und der Zugriff darauf manuell eingeschränkt. Erkennt das System einen nicht autorisierten Zugriff, erfolgt Meldung, und verschiedene Maßnahmen werden sofort automatisiert eingeleitet. Zum anderen lernt das System aber auch über die Zeit, welche User auf welche Daten in welcher Art zugreifen. Diese erlernten Zugriffsmuster (Anlernphase mindestens 2-4 Wochen) werden in Echtzeit mit den realen Datenströmen und -zugriffen verglichen. Meldung und automatische Maßnahmen erfolgen auch in diesem Fall, wenn das System Abweichungen von üblichen, erlernten Mustern erkennt. Verdächtig veränderte Daten werden in Quarantäne gesteckt und können aus schreibgeschützten Snapshots sofort wieder hergestellt werden.
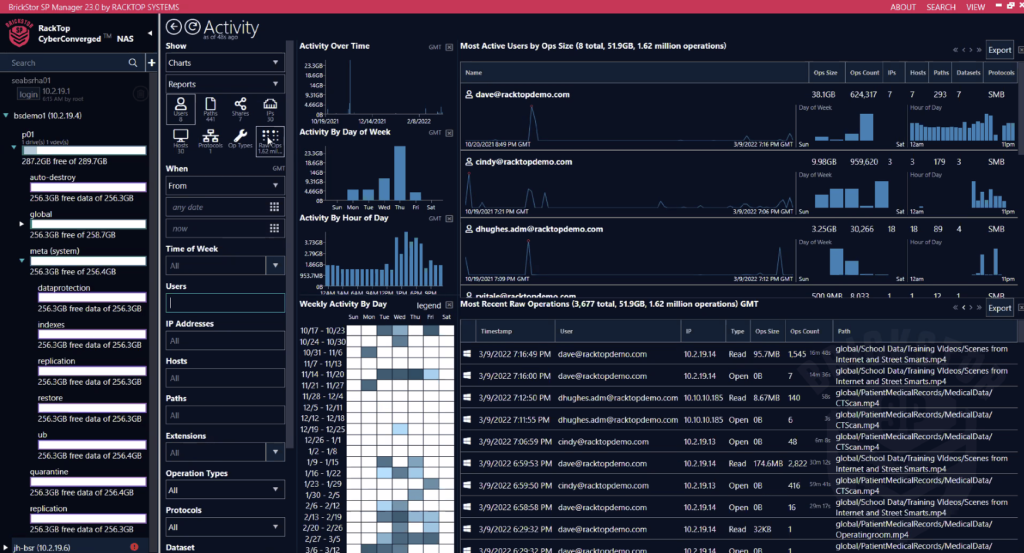
Auf Powerpoint hört sich das alles ganz toll an. In der Praxis kommt das System als Gateway (Appliance oder virtuelle Maschine), für eine sinnvolle und umfangreiche Analyse müssen sämtliche Daten einmal durch das Gateway. Das kann zu einem Bottleneck werden und ggf. Performance eines darunter liegenden Storage-Systems zunichte machen. Mit meiner deutschen Unternehmensbrille gebe ich außerdem zu bedenken: Die Admins einer solchen Appliance können während des Betriebs sehr genau und in Echtzeit verfolgen, welcher Benutzer gerade an welchen Dateien oder Dokumenten arbeitet. Das ruft schnell Betriebsräte und Datenschützer auf den Plan. wer über solche Lösungen nachdenkt, tut deshalb gut daran, entsprechende Organe innerhalb des Unternehmens frühzeitig in den Beschaffungsprozess mit einzubeziehen.
Alle Präsentationen von RackTop Systems auf dem Storage Field Day 23 sind nachzusehen auf der Webseite des Tech Field Day.
Globalisierung galore: Global File System von Hammerspace
Zum Tagesabschluss wurde die Schwerkraft aufgehoben. So jedenfalls eine markige Aussage von Hammerspace („Eliminate Data Gravity“). Etwas weniger markig geht es darum, über die in verschiedenen Datensilos untergebrachten Daten eines Unternehmens eine intelligente Schicht zu legen, um z. B. einen einheitlichen Namespace über alles zu haben, um Metadaten zu verwalten, Datenströme zu automatisieren und noch ein paar Dinge mehr. Es ist dabei in der Tat relativ egal, in welchem Silo oder Topf Daten liegen: NAS-Filer, Block-Storage, Object-Storage im eigenen Rechenzentrum, Object-Storage bei einem Cloud-Anbieter.
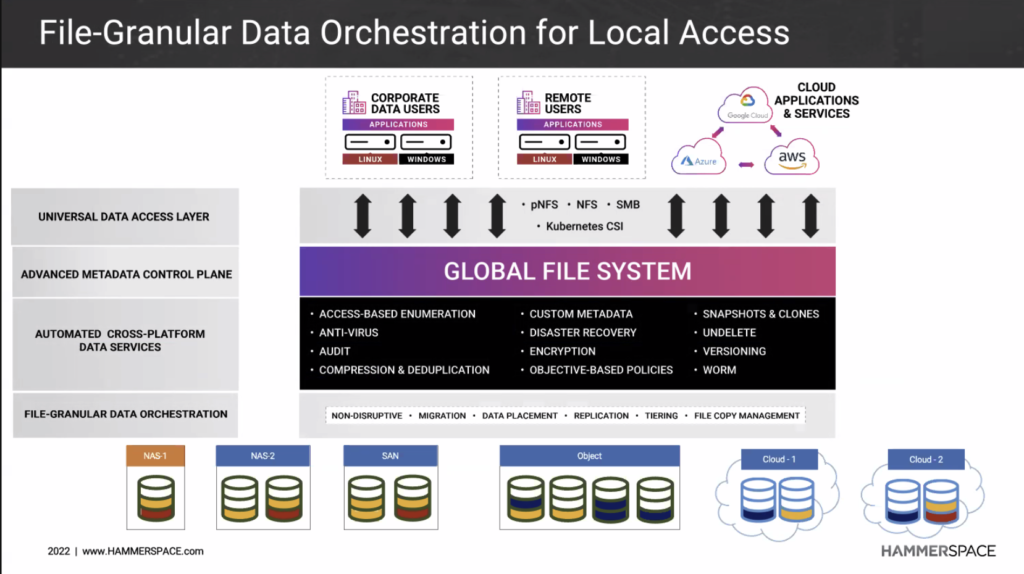
Mit den integrierten Data Services eröffnen sich vielfältige Möglichkeiten zu automatisierter Datenmanipulation. Einer der geschilderten Anwendungsfälle: Entstehende Daten an einem Ort A irgendwo auf unserem Globus automatisiert an einen ganz anderen Ort B zu übertragen, weil die zur Verarbeitung notwendige Rechenleistung am Ort B sehr viel günstiger ist als an Ort A. Ähnlich sind ganze Verarbeitungsketten denkbar, ebenso wie automagische Archivierung, die Bereitstellung von Clones für Entwicklungs- oder Testabteilungen und vieles mehr.
Der Technology Scout denkt, vom Grundgedanken her ist das eine wirklich schöne Idee, der Teufel steckt aber in den Details. Globales Locking ist solange kein Problem, solange zu einem Zeitpunkt eine Datei nur von einer einzelnen Person (oder einem einzelnen Algorithmus) bearbeitet wird. Angeblich sei das gelöst, Details blieb man uns schuldig, was aber auch am eng gesteckten Zeitrahmen liegen könnte. Nutzt man Cloud-Storage, kann ein unbedacht konfigurierter Automatismus schnell unerwartet hohe Egress-Kosten zur Folge haben.
Alle Präsentationen von Hammerspace auf dem Storage Field Day 23 sind nachzusehen auf der Webseite des Tech Field Day.
