VAST Data reduziert die Daten. Damit will es All-Flash-Arrays (AFA) so günstig machen wie HDD-Speicher. Außerdem adressiert das Unternehmen gleich noch ein paar andere Herausforderungen im SDS-Markt.
Was ist SDS?
Bei Software-defined Storage (SDS) ist die Lizenz der Storage-Software nicht an eine bestimmte Hardware gebunden. Das unterscheidet SDS vom traditionellen Appliance-Ansatz, bei dem Unternehmen von einem Hersteller immer ein komplettes Bundle aus Hardware und Software beziehen mußten. Die Folge war eine hohe Abhängigkeit (Vendor-Lock-in) und umständliche sowie kostspielige Upgrades: meist mußte die ganze Box ausgetauscht werden. SDS erlaubt die Weiterverwendung bestehender Systeme (Investitionsschutz) oder den Einsatz günstigerer, auf offenen Standards basierender Hardware.
Aber, aber, aber…
Es gibt natürlich auch ein paar Nachteile. Beim Appliance-Ansatz ist die Software auf die Hardware optimiert. Das macht die Systeme extrem effizient. Da beim SDS der Software-Entwickler nicht weiß, auf welcher Hardware sein Produkt eingesetzt wird, entscheidet er sich für den kleinsten gemeinsamen Nenner. Der Code wird nicht mehr für einen bestimmten Prozessor oder einzelne SSD- oder HDD-Modelle optimiert. Im Zweifel erschlägt ein Anwender Performance-Einbußen mit Blech. Oder der Entwickler optimiert seinen Code für die am meisten verbreitete Hardware und schränkt die Nutzung (eigentlich seine SLA) mit HCLs (Hardwarekompatibilitätslisten) ein. Das ist dann fast wieder ein Appliance-Ansatz. Zudem kosten HCL den Entwickler zusätzlich Geld für Zertifizierungen und Tests von Hardware. Rate, wer das am Ende mitbezahlt.
Und auch HCL schützen nicht gänzlich vor Inkompatibilität: Unternehmen können äußerst kreativ sein und einzigartige Kombinationen einzelner unterstützter Komponenten zusammenstellen, welche der Softwareanbieter im Leben nie miteinander so einsetzen würde und natürlich auch nicht getestet hat. Das lustige Spiel des Support-Ping-Pong ist vorprogrammiert. Als Unternehmen sollte man sich auch nicht darauf verlassen, dass der Softwareanbieter ihr spezielles System im Lab 1:1 nachbauen kann, um das Problem zu reproduzieren.
Referenzarchitekturen oder OEM-Appliances lösen diese Probleme nur bedingt. Auch diese lassen viel Raum für Schuldzuweisungen bei der Problemverantwortung und -lösung. Letztlich liegt beim SDS die Verantwortung für ein Storage-System komplett beim Kunden. Fehlt fundiertes Storage-Knowhow im Unternehmen, gibt man am Ende deutlich mehr Geld aus als für einen guten alten Storage-Monolithen. Vom Zeitaufwand und den Nerven ganz zu schweigen.
Es geht auch anders
VAST Data entwickelt in erster Linie Software. Genau genommen entwickelt der SDS-Spezialist ein Universal Storage-Softwareprodukt, welches Datei- und S3-Speicher auf zertifizierten Hardwarekonfigurationen von Partnern wie Avnet bereitstellt. Das Konzept basiert auf der Disaggregated-Share-Everything-Architektur (DASE).
Die zustandslosen Rechenknoten in einem VAST Storage-Cluster sehen immer die gesamte NVMe-SSD-Kapazität. Anwendungen werden in Serverpools auf einer skalierbaren All-Flash-Plattform konsolidiert. Serverpools stellen dedizierte Ressourcen für anspruchsvolle Anwendungen oder Mandanten bereit und lassen sich je nach Anforderungen der Anwendungen leicht nach oben und unten skalieren.
VAST setzt vor allem auf schnelles Netzwerk (NVMe-oF) mit kostengünstigem Flash und Storage Class Memory (SCM). Das ermöglicht neue algorithmische Konzepte, z. B. für die Datenreduzierung. VAST senkt damit die Kosten pro TB auf das Niveau von Nearline-Disks.
In der Hardware kommen QLC-SSDs zum Einsatz. VAST hat die Schreibvorgänge an die internen Flash-Strukturen in diesen SSDs angepasst. So lässt Write Amplification verhindern, die bei einer internen Garbage Collection auf SSDs entsteht.
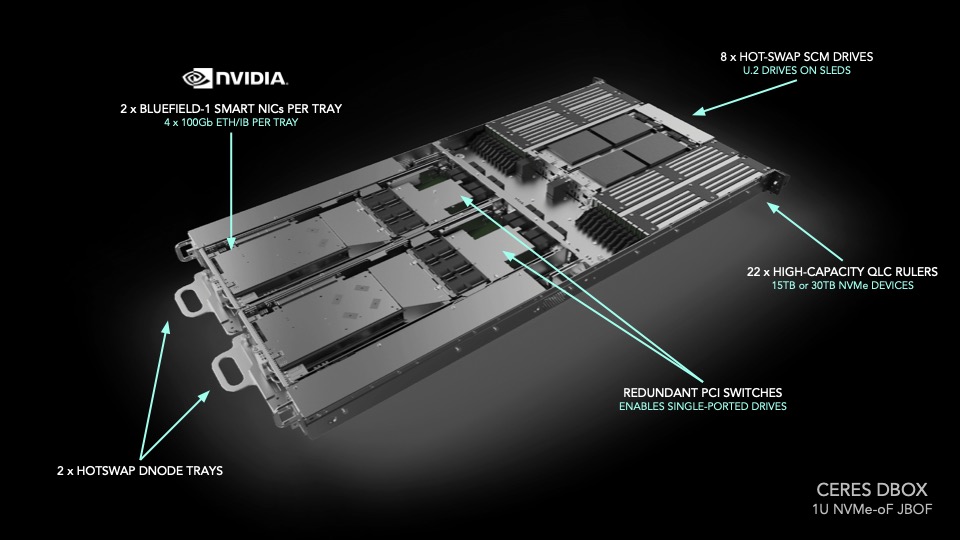
VAST setzt auf nur eine einzige Datenschicht. Für Metadaten und Queuing eingehender Schreibvorgänge ist das SCM zuständig. Tiering, wie bei vielen SDS-Anbietern, ist nicht notwenig.
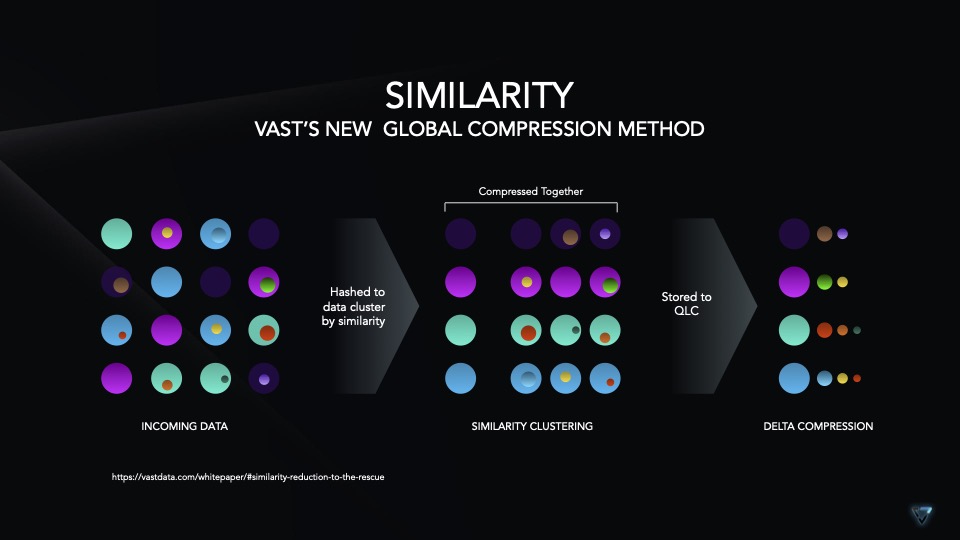
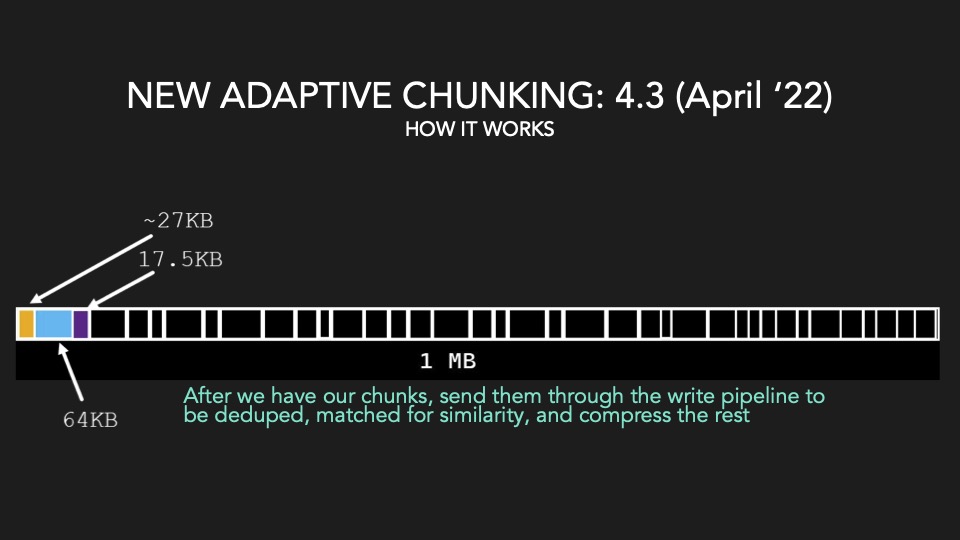
Mit dem aktuellen QLC-NAND (4 Bits/Zelle) erreicht VAST VAST eine Datenreduktion von 3:1, was bei 12 PB Rohdaten eine effektive Kapazität von 36 PB bedeutet. Erreicht wird das u. a. durch die Verwendung von Similarity Hashing und adaptivem Chunking (variable Blocklänge).
Similarity Hashing ist eine neue Global Compression Methode, bei der einkommende Daten nach Ähnlichkeit zusammengefasst werden. Ähnliche Daten lassen sich i. d. R. besser komprimieren (Delta). Mit den variablen Blockgrößen beim Adaptive Chunking entfällt das Padding. Seit Version 4.4 ist auch Data Awareness integriert. Damit lassen sich Integer und Float in Daten erkennen und optimiert ablegen. Vor allem Market Data, Life Science Data und Data Warehouses profitieren davon. Einkommende Daten werden vor dem Similarity Hashing dedupliziert. Der Rest, was nicht zusammengefasst werden kann, wird zum Schluß auch noch komprimiert.

Auf der Roadmap stehen noch spezielle Komprimierungsalgorithmen für Bilder und andere Dateiformate, die bisher als unkomprimierbar galten. VAST geht davon aus, mit den neuen Algorithmen das Datenreduzierungsverhältnis auf 4:1 bis 5:1 steigern zu können, so dass noch weniger physisches QLC gebraucht wird. Noch weiter reduzieren ließe sich das mit PLC-Flash (5 Bits/Zelle). Damit könnte VAST sogar kostengünstiger als Nearline SAS werden.

Wolfgang erklärt xLC auf dem data://disruped®-Summit in Leipzig:
Partners first!
Neben innovativen Hardware-Herstellern, einem globalen Netz von Value added Resellern (VARs) pflegt VAST auch diverse Software-Partnerschaften. Das Partnernetz wartet mit großen Namen auf: Splunk, Veeam, Commvault oder Rubrik. Seit kurzem gehört auch Atempo dazu. Mit deren Datenmanagement-Plattform Miria können VAST-Kunden ihre Daten auf und von jedem Dateispeicher inkl. Tape oder in die Cloud verschieben. Vast Data kann auch als Backup-Ziel für die Datensicherung mit Atempo verwendet werden.
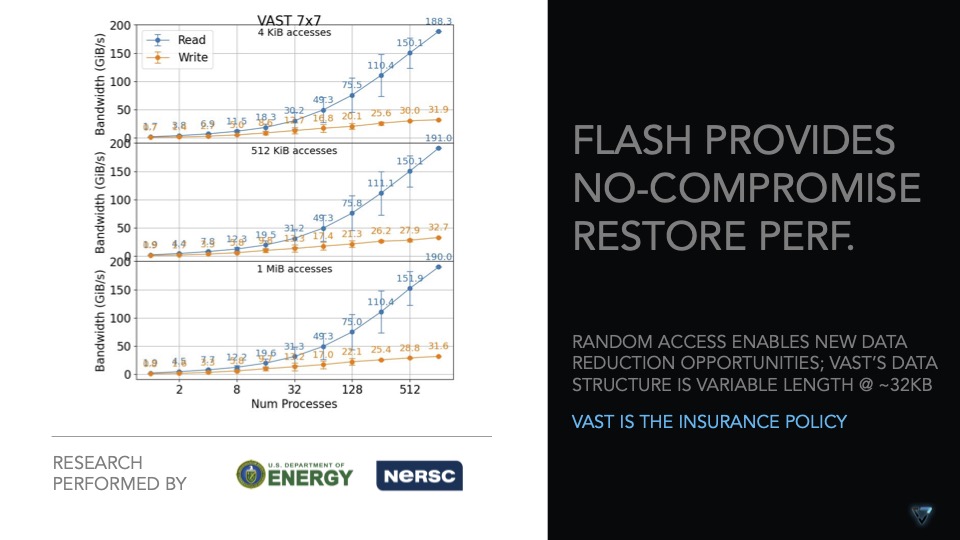
Kunden profitieren von der kostengünstigen Bereitstellung eines All-Flash-Backup-Ziels. Die Wiederherstellung von Daten aus All-Flash-Arrays ist um ein vielfaches schneller als von HDD oder gar Tape.