Ein analytisches Informationsionssystem oder Business Intelligence (BI) unterstützt Unternehmensverantwortliche mit aussagekräftigen Reports, Modellierung (Digital Twin) oder Predictive Analysis bei der Entwicklung einer Strategie, der Beschaffung oder Anpassung von Geschäftsprozessen. Je mehr Daten zur Verfügung stehen, desto besser sind die Ergebnisse.
Mit zunehmender Verbreitung künstlicher Intelligenz wird auch BI immer attraktiver und mit ihr Datenwarenhäuser – zentrale Plattformen, in den die Informationen zusammengeführt, korreliert und analysiert werden. Eines der bekanntesten Data Warehouses ist sicher die SAP Data Warehouse Cloud – Grundlage für SAP S/4HANA. Allerdings steht das ausschließlich dem SAP-eigenen Dienst zur Verfügung. Für ein möglichst breites Spektrum an Daten und unternehmens- bzw. bereichsübergreifende Analysen setzen daher viele Unternehmen auf unabhängigere Cloud-Plattformen wie Snowflake.
Vom Datensumpf zur Business Intelligence
Unternehmen speichern und verarbeiten enorme Mengen an unstrukturierten und strukturierten Daten, Tendenz steigend. Vor allem die Masse unstrukturierter Daten steigt rasant. Diese Daten haben naturgemäß unterschiedliche Formate und Schemata. Man spricht in dem Zusammenhang of von Datenseen oder -ozeanen (Data Lake, Data Ocean).
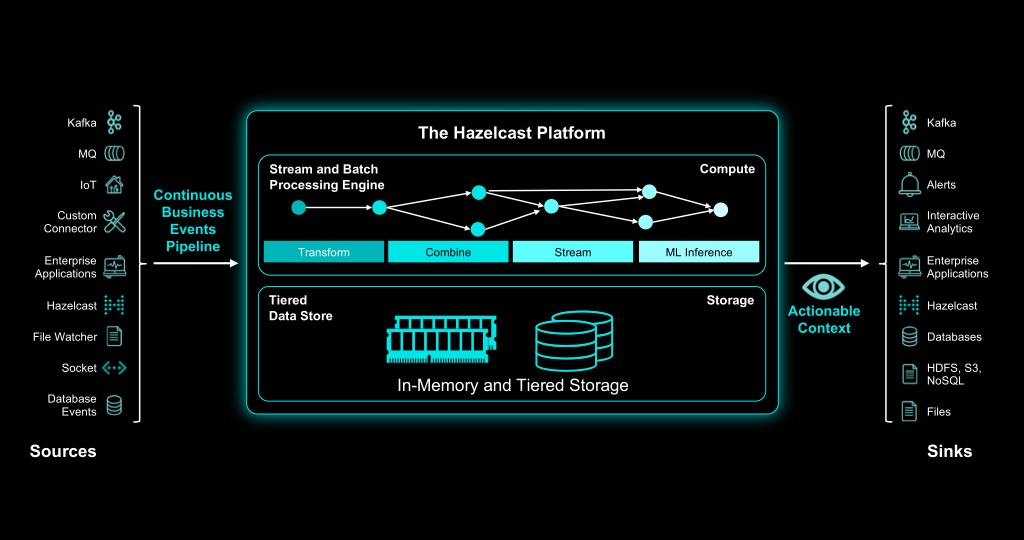
Die Analyse der Daten kann inline oder offline erfolgen. Wobei offline auch eine Cloud-Instanz sein kann. Inline-Verarbeitung hat den Vorteil, dass Ergebnisse in Echtzeit zur Verfügung stehen. Das ist vor allem in Bereichen wichtig, in denen sofort auf Daten reagiert werden muss – z. B. bei Netzwerk Detection & Response in der IT-Sicherheit. Ein Beispiel für eine solche Echtzeit-Stream-Processing-Plattform ist Hazelcast 🌐.
Für die meisten Business-Intelligence-Anwendungen ist eine Echtzeitverarbeitung nicht notwendig. Dennoch lohnt es sich, die Daten für die Analyse zu selektieren und in eine spezielle Datenbank zu übertragen, die für eine schnelle Verarbeitung großer Datenmengen optimiert ist: in ein Data Warehouse. Die Daten werden für das Data Warehouse bereinigt und strukturiert, was Big-Data-Anwendungen ihre Arbeit erleichtert. Zudem können in einem Data Warehouse Daten über mehrere Jahre hinweg gesammelt werden. Damit lassen sich z. B. später Trends ableiten und Vorhersagen treffen.
Eine Variante von Datenwarenhäusern sind Data Marts. Diese beziehen ihre Daten meist aus weniger Quellen und konzentrieren sich auf einzelne Bereiche wie etwa Sales, HR oder Marketing.

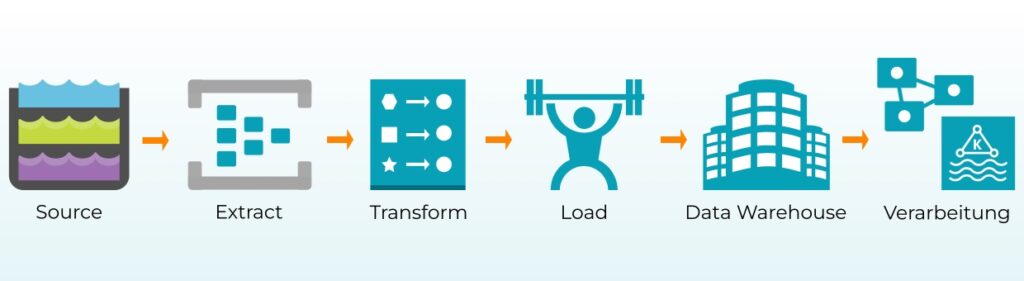
Data Warehouses und Data Marts beziehen ihre Daten aus verschiedenen internen und externen Datenquellen. Auf Grund der unterschiedlichen Dateiformate und -strukturen ist das nicht so ohne weiteres möglich. Bevor die Daten für die Verarbeitung in ein Data Warehouse geladen werden können, müssen sie extrahiert und transformiert werden. Dieser Prozess ist als ETL bekannt. In einigen Szenarien wie bei der Echtzeitverarbeitung können Daten auch zuerst geladen und anschließend transformiert werden (ELT).
Zu den bekanntesten Anbietern von Data Warehouses gehören Snowflake, Cloudera, Google BigQuery, Teradata oder Amazon Redshift. Da wir immer auf der Suche nach europäischen bzw. sogar deutschen Anbietern sind, fiel uns das Berliner Startup DoubleCloud 🌐 auf. Die starke Fokussierung des Anbieters auf Werbetreibende sowie mobile, Gaming- und Web-Apps ist allerdings eine große Einschränkung, weswegen wir den Anbieter eher als Data Mart einstufen.
DoubleCloud setzt – wie die meisten Data Marts oder Warehouses – auf die großen Hyperscaler. Aktuell ist DoubleCloud auch nur auf AWS verfügbar. Azure und Google (GCS) stehen auf der Roadmap. Alle Produkte bei DoubleCloud sind managed Services. Dabei setzt das Unternehmen auf Open-Source-Technologie wie Kafka oder das selbst entwickelte OLAP-DBMS (Online Analytical Processing Database Management System) ClickHouse.
Sobald die Daten korrekt im Data Warehouse gespeichert sind, können sie mit Business Intelligence (BI)-Tools analysiert und visualisiert werden.
Stefan Käser, Solution Architect bei DoubleCloud
Die Analyseergebnise können mit der DoubleCloud-Visualisierung angezeigt werden oder mit 3rd-Party-Tools (BYOT).
Die Preise starten für Clickhouse bei knapp 50 EUR für 1TB Daten auf einem Host mit der kleinsten Rechenleistung (2 Cores, 4 GB RAM). Dazu kommen die Kosten für die AWS-Services. Hat man keinen eigenen AWS-Account und nutzt den Service von DoubleCloud, geht’s bei etwas über 120 Euro los. Für eigene Kalkulationen bietet das Unternehmen einen Kalkulator 🌐 auf der Website.
Qualität vor Quantität
Übrigens ist jede Datenquelle nur so gut, wie sie gepflegt wird. Je größer der Datenozean, desto wichtiger sind Metadaten und Data Governance. Metadaten helfen bei der Wiederaufindbarkeit. Data Governance regelt, wer welche Daten sehen kann, wer darauf zugreifen und sie bearbeiten, verschieben oder sogar löschen kann, wo sie gespeichert werden bzw. welche Daten von wem wie lange gespeichert werden sollen. Je mehr Daten ein Unternehmen speichert, desto eher lohnt sich die Investition in ein gutes Daten-Management-System, wie Data Dynamics oder Alation.