Eine Case Study der UK National Supercomputing Facility an der Durham University machte uns auf Liquid aufmerksam. Mit der COSMA 8 (COSmological MAchine) für Large Scale Simulations wie die Entwicklung des Weltraums vom Urknall bis zu seiner aktuellen Ausprägung. Diese Simulationen sind teilweise extrem speicherhungrig oder GPU-lastig.
Wenn wir diese großen Simulationen durchführen, sind einige Bereiche des Universums mehr oder weniger dicht, je nachdem, wie die Materie kollabiert ist. Die sehr dichten Bereiche erfordern mehr Arbeitsspeicher für die Verarbeitung. Dank der Kompositionsfähigkeit können die Ressourcen zu diesen Zeiten verschiedenen Arbeitslasten zugewiesen und der Speicher zwischen den Knoten geteilt werden. Wenn wir die Simulation formatieren und zu Bereichen kommen, die mehr Arbeitsspeicher benötigen, müssen wir die Dinge nicht physisch verschieben, um diesen Teil der Simulation zu verarbeiten.
Alastair Basden, Technical Manager DiRAC* Memory Intensive Service an der Durham University
SLURM!
Das Problem sind der hohe Bedarf an teuren Komponenten (GPU, RAM) und deren bestmögliche Ausnutzung. Mit Liqid CDI Software/Hardware lassen sich HW-Komponenten on demand zusammenschalten, ohne dass sie physisch bewegen oder montieren zu müssen.
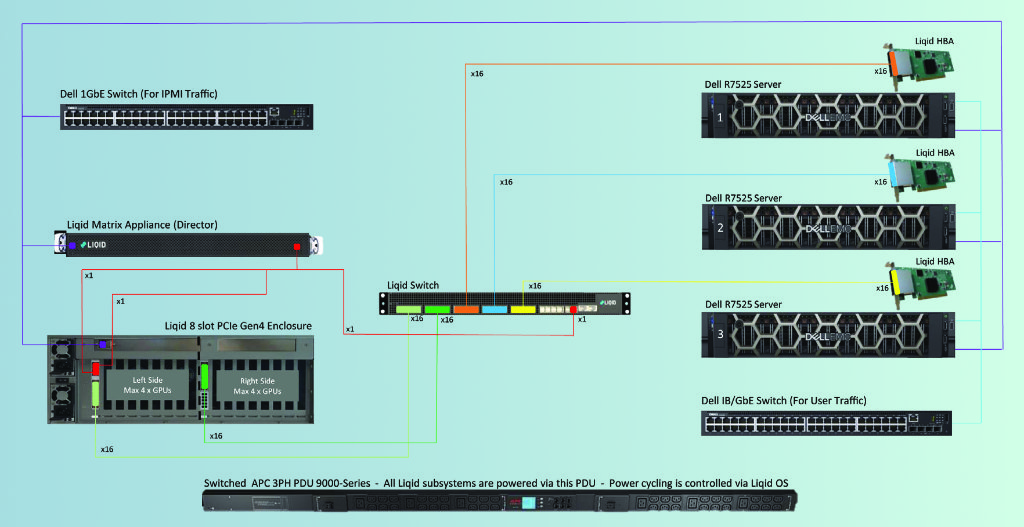
Durham University’s Liqid Composable Solution (Quelle: Liqid)
Software Defined Infrastructure
Realisiert wird das Ganze über ein switched PCIe Network. Der Aufbau ist identisch bzw. ähnlich zu SAN, Ethernet und Infiniband. Für die Compute Nodes braucht es einen PCIe HBA. Aktuell gibt es die Ver Versionen PCIe 3.0 und PCIe 4.0, PCIe 5.0 wird ab ca. 1HJ/2023 verfügbar sein, wenn die ersten Server- und Storage-Systeme das auch unterstützen. Der PCIe Switch ist ein Liqid Grid in 24/48 Ports Ausführung. Für die Aufnahme der GPU, FPGA, NVMe SSDs oder SCM-Module (Storage Class Memory) sind PCIe Expansion Chassis in diversen Größen verfügbar. Die Liqid Matrix Software unterstützt slurm für das Workflow-Management und VMware (vCenter Plugin). OpenStack/K8S-Support steht auf der Roadmap.
Derzeit dürfte das switched PCIe etwas Proprietäres sein. Der zukünftige Standard dürfte Compute Express Link (CXL) sein.
Mit Liqid lassen sich die Vorteile der Cloud (Flexibilität, Skalierbarkeit, Agilität) on premises nutzen – zu einem Bruchteil der Kosten. Nachteil: Man muss sich selbst drum kümmern, seine Anforderungen (!Workloads) genau kennen und wenigstens ansatzweise Ahnung von Compute- und Storage-Architektur haben.
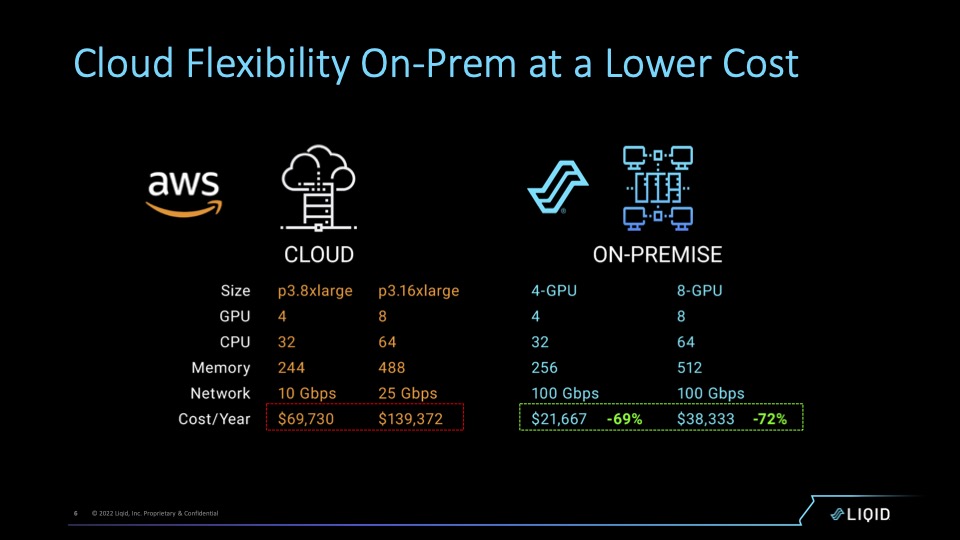
Die komplette Case Study findest du online. In einem White-Paper von ESG sind die Auswirkungen von composable infrastructure auf die Nachhaltigkeit zusammengefasst.
Und wer ist jetzt Slurm?! Einige von euch kennen den Slurm Workload Manager möglicherweise noch als Simple Linux Utility for Resource Management (SLURM). Mit Slurm lassen sich u. a. zeitabhängig Ressourcen bestimmten Jobs zuweisen und die Warteschlange verwalten. Der Job Scheduler für Linux und Unix-Derivate ist auf etwa 60% der Top 500 Supercomputer im Einsatz.
* DiRAC bedeutet Distributed Research Utilising Advanced Computing System.


