
Ein Referenzmodell
In diesem ersten Artikel geht es um die Cloud-Architektur. Der Artikel bildet die Grundlage einer kleinen Serie, in der es final tatsächlich um Storage gehen wird.
Immer mehr etablierte Storage-Anbieter bewegen sich in Richtung cloud-native. NetApp, Nexenta oder IBM sind die prominentesten Beispiele. Und bei fast allen spielt Open Source eine große Rolle. IBM hat mit Red Hat sogar gleich einen ganzen Open-Source-Zoo eingekauft. Wie hängt das alles zusammen? Wie kommen die Daten in die Cloud – und noch viel wichtiger – auch wieder aus der Cloud heraus? Dazu schauen wir uns zunächst einmal an, wie eine typische Cloud aufgebaut sein kann.
Cloud Computing ist keineswegs eine Erfindung des 21. Jahrhunderts. Bereits 1943 setzte das britische Militär in Bletchley Park auf zentrale Rechenpower. 1983 erlaubte Control Data erstmals den parallelen Betrieb eines 60- und eines 64-bit-Betriebssystems gemeinsam auf einer CPU. 1999 ermöglichten Java und ActiveX den Zugriff auf Großrechner via Browser oder Tablet. Und keine zwei Jahre später haben Worldcom und Digex den Traum vom Application Hosting realisiert. Auch wenn das damals alles noch ganz anders hieß, und sich die Technologie inzwischen rasant weiterentwickelte, sind die Prinzipien gleichgeblieben: Irgendwer greift von irgendwo mit irgendetwas auf zentrale Computer und Daten zu. Es geht um Virtualisierung, Automation und Effizienz. Storage-Forum hat genauer hingeschaut, wie Cloud Computing fast 80 Jahre nach Colossus heute aussieht.
Die Cloud. Was ist das eigentlich?
Cloud Computing ist das komplexe Zusammenspiel vieler einzelner Hard- und Software sowie Netzwerk-Komponenten. Wie komplex eine Cloud aufgebaut sein kann, zeigt das folgende Bild:
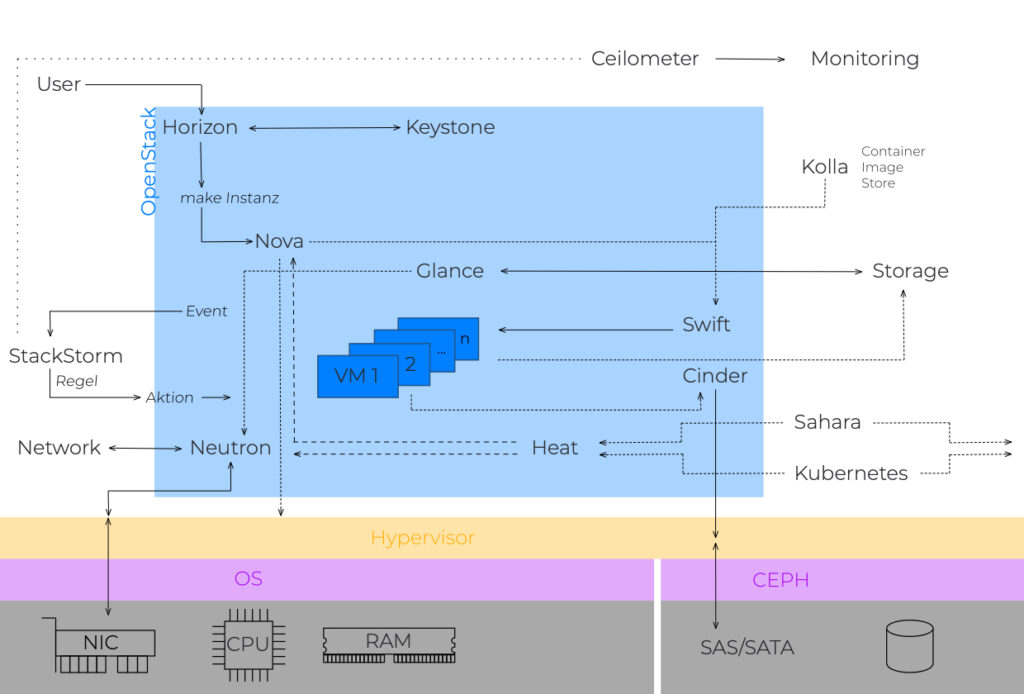
In diesem Artikel wollen wir über die grundsätzliche Funktionsweise sprechen. In weiteren Artikeln werden wir auf einzelne Aspekte detaillierter eingehen – um am Ende doch nur über Storage zu sprechen.
Der Cloudstack
Eine Cloud besteht aus mehreren Schichten. Jede einzelne Schicht (Layer) stabilisiert die Cloud und macht sie robust gegenüber Fehlern oder Ausfällen. Der Aufbau ist für alle Arten der Cloud gleich, egal ob public, private oder hybrid.
Physik
Im physischen Layer, der Hardware-Schicht, finden wir Prozessoren (CPU) für Rechenleistung, Netzwerkinterfaces (NICs) für die Konnektivität, Arbeitsspeicher (RAM) und Platten für das Speichern der Daten.
Hardware-Management
Im Management-Layer finden wir Betriebssysteme (Operating System, OS), Treiber und Netzwerkintelligenz. In diesem Layer werden Hardware und Storage sowie die Verteilung der Daten im Netzwerk verwaltet. Robuste, verteilte Dateisysteme wie Ceph adressieren Objekt-, Block- und File-Storage in einem einheitlichen System.
Virtualisierung (Hypervisor)
In dem darüber liegenden Virtualisierungslayer erzeugt ein Hypervisor virtuelle Maschinen und steuert deren Betrieb. Dabei wird zwischen zwei Typen unterschieden: Hypervisor des Typ 1 laufen direkt auf der Hardware. VMware ESXi, Microsoft HyperV oder VMware vSphere sind typische Vertreter dieses Typs. Hypervisor des Typ 2 sind in Betriebssysteme integriert. Oracle VM VirtualBox, KVM oder VMware Fusion sind die bekanntesten. Hypervisor des Typ 2 fand man in der Vergangenheit eher in kleineren Umgebungen, da sie nicht so hoch skalieren wie die Baremetal-Hypervisor des Typ 1.
Das änderte sich 2013 mit der Veröffentlichung von Docker. Docker ist eine Containervirtualisierung (Containering), die ebenfalls bereits im Betriebssystem integriert ist. Im Gegensatz zur Virtualisierung mittels Hypervisor ist Containerisierung schlanker, also ressourcenschonender. Gäste in Containern greifen direkt auf den Kern des Host-OS zu. Neu bei Red Hat ist Podman. Es gab bereits vor Docker solche Ansätze. Die Veteranen unter uns kennen sicher noch BSD Jails oder Solaris Zones. Container gelten aufgrund ihrer Isolation als sehr sicher. Ein Nachteil besteht allerdings darin, dass bei Bekanntwerden einer Schwachstelle alle Instanzen einzeln patched werden müssen, da jede Instanz auf eigene Bibliotheken zurückgreift.
Orchestrierung (Cloud-Basis-Layer)
Dieses Layer verwaltet und kombiniert automatisiert physische Ressourcen, virtuelle Maschinen und Dienste. Dazu gehört u. a. das Bereitstellen von Servern und virtuellen Maschinen, die Verwaltung von Netzwerken und Diensten oder das Zuweisen von Speicherkapazität. Start und Stopp oder ein Durchbooten virtueller Instanzen werden ebenfalls zentral in dieser Ebene gesteuert. Dabei kann die Steuerung per Web- oder graphischem User Interface (UI) erfolgen.
Für die Automatisierung eignen sich Werkzeuge wie Ansible, Chef oder SaltStack. Container werden in den meisten Fällen mit Kubernetes orchestriert. Die automatisierte Verwaltung der Instanzen wird via Schnittstelle oder Kommandozeile (Command Line Interface, CLI) realisiert.
Zur Orchestrierung gehört auch die Zugangsverwaltung und Verwaltung der Benutzerrollen für graphische Oberflächen (GUI), die Schnittstellen (API) und selbstverständliche die Administratoren der einzelnen Hosts.
Das Cloud-Betriebssystem
Als Cloudbetriebssystem hat sich OpenStack weitgehend durchgesetzt. In OpenStack ist eine Vielzahl an Komponenten vereint, die sich z. B. um Virtualisierung und die Bereitstellung von Storage kümmern. Im Einzelnen sind das:
- Nova verwaltet virtuelle Maschinen.
- Glance registriert, findet und empfängt Images als Vorlage für die schnelle Bereitstellung neuer virtueller Instanzen. Images können lokal vorgehalten werden aber auch via Swift oder Ceph aus Objektspeichern gezogen werden. Glance hält auch Metadaten wie das verwendete Betriebssystem oder Kernelversionen vor.
- Keystone dient als Authentifizierungs- und Rechtesystem.
- Den Netzwerkdienst stellt Neutron bereit.
- Swift stellt virtuellen Maschinen den lokalen Storage zur Verfügung. Der Objektspeicher dient auch als Backend für Cinder und Glance.
- Cinder stellt virtuelle Speichermedien bereit. Via Swift können die Blockspeichermedien mit dem Objektspeicher kommunizieren.
- Horizon schließlich ist das Dashboard von OpenStack. Das Webinterface dient zur Verwaltung der OpenStack-Cloud und zur einheitlichen Darstellung der wichtigsten Funktionen. Templates bieten die Basis für optische Anpassungen oder eigene, funktionale Erweiterungen (Customizing).
Für Zugriffe sowie die Verwaltung von außen wird vorrangig die REST-Schnittstelle verwendet. REST (Representational State Transfer) ist abstrahiert von WWW-Architektur und -Mechanismen. Die RESTful oder REST API funktioniert mit herkömmlichen HTTP-Aufrufen (GET, PUT, POST, DELETE) und stellt so ein hohes Maß an Interoperabilität sicher. Auch der Zugriff auf Container oder Objekte in der Cloud erfolgt über die REST API.
Monitoring
Das Monitoring der Cloud erlaubt Einblicke in Leistung, Verfügbarkeit und Zustand der einzelnen Cloud-Komponenten inkl. physischer Layer bis in die Anwendungsebene. Führend ist seit einigen Jahren die Open-Source-Lösung Prometheus. Auf Grund seiner Überwachungstiefe und Granularität gilt es fast schon als Business-Intelligence-Plattform. Wir werden dem einen eigenen Artikel widmen.
Provisioning (auch Scalable oder Cluster-Ebene)
Das Provisioning regelt u. a. auch die Zugangskontrolle nach der groben Einteilung in Anwender, Mandanten und Administratoren. In dieser Ebene werden Ressourcen allokiert, die Verwaltung der Cloud automatisiert und Web- sowie graphische Oberflächen für das Cloudmanagement bereitgestellt.
Infrastructure as a Service
Die unteren Ebenen der Cloud (physische Ebene inkl. Netzwerk und Storage sowie der Virtualisierungslayer) bilden die Grundlage von Infrastructure as a Service (IaaS). IaaS ist das Angebot von Rechenleistung und Speicher nach Bedarf. Viele Unternehmen nutzen dieses Angebot als Basis für den Aufbau ihrer eigenen IT-Services.
Als Software für die Realisierung eigener Cloudlandschaften auf Basis von Infrastrukturen großer Anbieter wie AWS hat sich Eucalyptus durchgesetzt. Es dient als Cloud-, Cluster- und Storage-Controller sowie als Vermittler virtueller Maschinen. Zur Bereitstellung von Storage nutzt Eucalyptus den eigenen Dienst Walrus, der vollumfänglich mit S3 kompatibel ist. Amazons Simple Storage Service (S3) ist einer der wichtigsten Storage-Dienst in der Amazon-Cloud. S3 war schon sehr früh verfügbar, die Schnittstelle ist ziemlich einfach, weshalb sie sich schnell verbereitete.
Cloud-Anwendungsebene
In dieser obersten Ebene finden sich schließlich die Anwendungen. Neben Geschäftsanwendungen sind das auch Umgebungen für Entwickler und Software der Cloudbetreiber selbst für Accounting und Abrechnung (Billing).
Software as a Service
Nutzt ein Unternehmen alle Ebenen des Cloudstacks, spricht man auch von Software as a Service (SaaS). Nutzer von SaaS betreiben i. d. R. keine eigenen zentralen IT-Services mehr und beziehen alle Anwendungen aus der Cloud. Auch alle Daten werden in Cloudumgebungen verwaltet und gespeichert. SaaS-Angebote richten sich nicht nur an Freiberufler, kleine oder mittelständische Unternehmen. Auch große Unternehmen greifen immer öfter auf diese Angebote zurück. Neben einem hohen Maß an Flexibilität spielen vor allem erhöhte Ansprüche an IT-Sicherheit und fehlende eigene Expertise in zunehmend komplexeren IT-Landschaften eine Rolle bei der Entscheidung. Die Konzentration der eigenen Haus-IT verlagert sich mehr und mehr auf die Bereiche, in denen die Wertschöpfung erfolgt.
Platform as a Service
Zwischen IaaS und SaaS ist Platform as a Service (PaaS) angesiedelt. Bei diesem Modell schätzen die Anwender die Verfügbarkeit zuverlässiger Laufzeitumgebungen. PaaS wird gern von Software-Entwicklern genutzt. Daten und Anwendungen verwalten sie selbst.
Welche Rolle spielt Open Source? Und was hat das alles mit Storage zu tun?
In unserer Cloud-Referenzarchitektur spielt Open Source eine sehr große Rolle. Offene Standards und quelloffener Code sind die Grundlage von Interoperabilität in immer größeren und immer heterogeneren Landschaften. Fast alle namhaften Cloudserviceanbieter setzen auf Open Source in ihren Backends. Große Player wie Google setzen sogar bei der Hardware auf offene Systeme. Über das Open Compute Projekt (OCP) werden wir an anderer Stelle detailliert berichten.
In unseren nächsten Artikeln werden wir die Angebote von NetApp, Rubrik, Red Hat OpenShift, Komprise und StrongBox detaillierter vorstellen. Alle diese Angebote haben eines gemeinsam: Sie speichern Daten flexibel in verschiedenen Clouds. Für das Verständnis fanden wir es hilfreich, erst einmal den grundlegenden Aufbau einer Cloud zu verstehen.
