
Daten sind ein wertvolles Kapital in Unternehmen. Die steigende Menge an Daten stellt viele Firmen vor große Herausforderungen, vor allem bei der Speicherung. Immer öfter wandern Daten daher in die Cloud.
Cloud-native Anwendungen und Speicherdienste sind generell robust. Das betrifft allerdings nur die Verfügbarkeit. Der Schutz der Daten vor unbeabsichtigtem Löschen, Kompromittierung oder Angriffen durch Viren oder Ransomware liegt in der Verantwortung des Eigentümers der Daten. Ein Verlust der Daten kann zu irreversiblen Schäden wie Produktionsausfällen, Umsatzeinbußen, schlechter Reputation bis hin zum Verlust von Kunden führen.
Nutzer von Cloud-Services benötigen Lösungen, die im Ernstfall sicher, einfach und schnell die Daten wiederherstellen können. Der Markt bietet eine Vielzahl an Werkzeugen zur Datenreplikation, Datenverwaltung, Datensicherung und Datenwiederherstellung für Unternehmen jeder Größe. Die meisten Cloud-Backup-Services ermöglichen die Sicherung und Wiederherstellung von Benutzer- und Anwendungsdaten. Eigenständige Dienste sind spezialisiert auf die Sicherung und Wiederherstellung für Office 365, SAP oder SalesForce.
In diesem Artikel erklären wir, wie Disaster Recovery (DR) in der Cloud funktioniert, wodurch es sich von herkömmlicher DR unterscheidet und was es zu beachten gilt. Abschließend beschreiben wir kurz, wie NetApp Cloud Volumes ONTAP Disaster Recovery mit Google Cloud funktioniert.

Feature: In unserem Video-Interview mit NetApps Cloud Ambassador, Problemlöser und Mentor Peter Wüst haben wir nachgehakt, wie ein typisches Szenario für ein Cloud-Setup mit NetApp aussieht, für wen es partout nicht geeignet ist und was sonst noch auf der Roadmap steht.
DR im Cloud Computing vs. herkömmlicher Disaster Recovery
Bei einer herkömmlichen Notfallwiederherstellung werden in der Regel Systeme neu installiert und konfiguriert und Daten aus dem Backup wieder eingespielt. Das ist eine sehr zeitaufwendige Angelegenheit, auch wenn dank Images und Automatisierung die Wiederherstellung ganzer Serverlandschaften mittlerweile viel schneller geht als noch vor ein paar Jahren. Die meiste Zeit kostet es, die Daten aus dem Backup wiederherzustellen. Datenmenge und technische Grenzen beeinflussen die Dauer der Wiederherstellung. Technische Grenzen können die Schreib- und Lesegeschwindigkeit eines Mediums sein, die für die Übertragung zur Verfügung stehende Bandbreite, aber auch die CPU-Leistung von Quell- oder Zielrechner. Je nachdem, wie oft Backups angefertigt wurden und wie gut die Daten im Backup geschützt sind, ergeben sich weitere Herausforderungen. Wie aktuell ist das Backup? Waren die Daten im Backup eventuell ebenfalls bereits Ziel eines Ransomware-Angriffes?
Die Bereitstellung von Disaster-Recovery-Umgebungen ist für die meisten Unternehmen eine Herausforderung. Einrichtung und Wartung physischer Standorte ist mit nahezu den gleichen Kosten wie für die gesamte Produktionsumgebung verbunden. Das ist gerade für junge und kleinere Betriebe nicht leistbar, zumal diese Standorte hauptsächlich im Leerlauf betrieben werden müssen.
Kaum ein Unternehmen leistet sich einen physischen DR-Standort in Form eines komplett eingerichteten Rechenzentrums mit ausreichender Server- und Storage-Kapazität, eigenem Wartungspersonal und Netzwerkinfrastruktur einschließlich Firewalls, Routern und Switches sowie einer zuverlässigen Internetverbindung mit ausreichender Bandbreite zwischen dem primären und dem sekundären Standort.
Hier bietet Cloud Computing mit skalierbaren Infrastructure-as-a-Service-Lösungen wesentliche Vorteile. DR-Umgebungen können sowohl für lokale als auch für Cloud-basierte Systeme erstellt werden. Wichtige Daten und Anwendungen werden im Cloud-Speicher vorgehalten, der im Katastrophenfall wie ein sekundärer Standort genutzt werden kann.
Rechenzentren großer Cloud Service Provider (CSP) sind hoch performant, sehr sicher und mehrfach redundant aufgebaut. Kontinuierliches Monitoring und modernste Technologie garantieren, dass Probleme oder Fehler von einem Cloudanbieter schnell erkannt und behoben werden. Darüber hinaus ist in der Cloud die Wartung der Plattform einschließlich Hardware- und Software-Upgrades rund um die Uhr gewährleistet.
Kritische Workloads können im Katastrophenfall schnell auf einen DR-Standort übertragen werden. Die Anwendungen greifen direkt auf die Daten im Backup zu. Der Geschäftsbetrieb kann innerhalb kürzester Zeit wieder aufgenommen werden.
Besonders lukrativ ist DR in der Cloud für kleine und mittelständische Unternehmen, die allgemein weder über ein ausreichendes Budget oder genügend Ressourcen für den Betrieb eigener, physischer DR-Standorte verfügen. Mit cloudbasiertem Disaster Recovery verschaffen sich Firmen ausreichend Zeit für den Wiederaufbau ihrer primären IT-Landschaft.
Kein DR ohne Notfallplan
Jedes Unternehmen sollte über einen umfassenden Disaster-Recovery-Plan verfügen. Der Plan muss neben der kompletten Infrastruktur auch potenzielle Bedrohungen und Schwachstellen, die wichtigsten Ressourcen und praktikable DR-Strategien inklusive der Reihenfolge der einzelnen Schritte zur Wiederherstellung berücksichtigen.
Die größte Herausforderung bei der Einrichtung und dem Betrieb eines DR-Standortes besteht darin, Daten aus der Produktionsumgebung zu synchronisieren und dauerhaft aktuell zu halten. Im Zuge der Einrichtung ist eine unabhängige, aktuelle Kopie aller Unternehmensdaten erforderlich, einschließlich:
- Datenbanksystemen,
- Dateidiensten,
- iSCSI-Speicher usw.
Daten, die sich ständig ändern, wie z. B. aus der Produktionsumgebung, müssen regelmäßig an den DR-Standort übertragen werden. Je aktueller die Daten und vollständiger die Dienste am DR-Standort sind, desto kürzer sind die Ausfallzeiten. Das ist jedoch immer auch eine Kostenfrage. Daher sollte jeder effektive DR-Plan die folgenden Schritte umfassen:
- Risikobewertung und Analyse der Auswirkungen unterschiedlicher Notfälle auf das Unternehmen
- Identifikation einzelner Präventions-, Reaktions- und Wiederherstellungsmaßnahmen
Im ersten Schritt wird die aktuelle IT-Infrastruktur bewertet und potenzielle Bedrohungen und Risikofaktoren identifiziert. Die Risikobewertung hilft, unternehmenskritische Funktionen und Anwendungen zu ermitteln sowie Schwachstellen in der IT-Infrastruktur zu erkennen. Daraus lassen sich Auswirkungen und Kosten eines teilweisen oder kompletten Geschäftsausfalls berechnen. Kennzahlen sind hier insbesondere das Wiederherstellungszeitziel (RTO) und das Wiederherstellungspunktziel (RPO). RTO ist die maximale Zeit, welche die IT-Infrastruktur ausfallen kann, bevor einem Unternehmen ernsthafte Schäden entstehen. RPO bezeichnet die maximale Datenmenge, welche aufgrund einer Unterbrechung verloren gehen kann.
RTO: Wie lange dauert es, bis der normale Betrieb nach einem Katastrophenfall wieder hergestellt ist?
RPO: Wie viele Daten kann ein Unternehmen während eines Katastrophenfalles verlieren?
Basierend auf RTO und RPO wird entschieden, welche Daten und Anwendungen wie geschützt werden müssen und wie viel in die Erreichung der DR-Ziele investiert werden sollte. Für einige Unternehmen sind diese Daten so wichtig, dass in einem DR-Ereignis kein Datenverlust toleriert werden kann.
Zur Erstellung des DR-Plans ist es notwendig, jeden Schritt des Wiederherstellungsprozesses zu dokumentieren. Nur so ist sichergestellt, dass der DR-Plan während einer Katastrophe auch ordnungsgemäß ausgeführt wird. Außerdem sollte der Plan neben Reaktions- und Wiederherstellungs- auch Präventionsmaßnahmen berücksichtigen. Prävention reduziert mögliche Bedrohungen und hilft, Systemschwachstellen zu beseitigen.
Im letzten Schritt werden die einzelnen Präventions-, Bereitschafts-, Reaktions- und Wiederherstellungsmaßnahmen (PPRR) und ihre Reihenfolge bei der Wiederherstellung festgelegt.
Wir empfehlen, Notfallpläne regelmäßig zu testen und zu aktualisieren. Bei den Tests helfen Simulationen in der Cloud. Ein Test des DR-Plans hilft, Probleme und Inkonsistenzen zu identifizieren. Dienstleister wie Cristie Data bieten DR-as-a-Service (DRaaS) inkl. Recovery Simulator für automatisierte Disaster Recovery Tests. Die Wiederherstellungssimulation kann auf virtuellen Maschinen oder in der Cloud abgebildet werden.
Bei der Anwendungswiederherstellung ist es wichtig, die DR-Maßnahmen auf Grundlage der Priorität einer Anwendung zu planen. Unser Beispiel basiert auf häufig verwendeten Anwendungen im Geschäftsumfeld:
- SAP
- Oracle Datenbank
- Exchange Server
- CRM
- MS SQL Server
- Microsoft SharePoint
Die einzelnen Schritte des Wiederherstellungsprozesses sollten so weit wie möglich automatisiert werden. Tests sollten je nach Unternehmensgröße spätestens alle drei Monate durchgeführt werden.
Auswahl geeigneter Lösungen
Die Vorteile für eine Migration von DR in die Cloud sind je nach Anforderung unterschiedlich. Neben geringeren Kosten ist vor allem die Reduzierung von Geschäfts- und Produktionsausfallzeiten von Bedeutung. Ein weiterer Pluspunkt für Cloud-DR ist eine benutzerfreundliche Plattform, die sich nahtlos in vorhandene IT-Frameworks einfügen lässt.
Folgende Kriterien sind bei der Auswahl einer geeigneten DR-Lösung zu beachten:
- SLA
- Reputation des Anbieters
- Benutzerfreundlichkeit der Lösung
- Einhaltung von Compliance-Richtlinien
- Grad der Automatisierung
- Einsatz
- Kosten
Die beim Anbieter eingesetzte Technologie spielt ebenfalls eine große Rolle. Kaum ein Unternehmen kann sich Ausfallzeiten von mehr als einem Tag leisten. Die meisten Unternehmen haben ein Zeitfenster von zwei bis vier Stunden zur Wiederinbetriebnahme kritischer Systeme. In manchen Fällen darf die Unterbrechung des Betriebs weniger als eine Stunde betragen. Aus Kostengründen setzen Cloudanbieter bei großen Datenmengen oft auf Tape Libraries. Bei RPO- und/oder RTO-Anforderungen von unter 24 Stunden ist bandbasiertes Vaulting jedoch ungeeignet. Das bedeutet allerdings auch: Je kleiner das Ausfallzeitfenster, desto höher ist der Preis.
NetApp ONTAP mit Google Cloud
Unabhängig davon, ob Sie Lösungen wie NetApp ONTAP lokal oder bereits in der Cloud mit z. B. Google Cloud ausführen, wird eine gute DR-Lösung für den Schutz der Daten benötigt. NetApp Cloud Volumes ONTAP unterstützt Unternehmen bei der Datenreplikation und Notfallwiederherstellung sowohl in lokalen (on-premises) als auch für Cloud-basierte Installationen des NetApp-Storagesystems.
Voll funktionsfähige DR-Sites sind nicht nur für ungeplante Ausfälle nützlich. Eine DR-Site live zu schalten hilft auch, Ausfälle durch z. B. Wartungsfenster für Aktualisierungen der primären Produktionsumgebung zu vermeiden. Die gleichen Failover- und Failback-Mechanismen werden auch im Katastrophenfall verwendet.
Failover: Übernahme aller Funktionen durch den DR-Standort.
Failback: Wiederherstellung des primären Standortes.
Für eine bessere Kosteneffizienz können DR-Systeme auch für periphere Anforderungen wie schreibgeschützte Berichte oder zum Einrichten von Testumgebungen für die Softwareentwicklung verwendet werden.
Disaster Recovery-Umgebungen müssen Redundanz auf Computer-, Netzwerk- und Speicherebene bieten.
Was sind die Bausteine einer Cloud DR-Umgebung?
Compute
Die CPU-Leistung, mit der Anwendungen ausgeführt werden, ist entscheidend für die Leistungsfähigkeit des sekundären Standortes. Anbieter wie Google bieten mit ihren Cloud Compute Engines flexible Cloud-Rechenressourcen. Assistenzsysteme helfen bei der Einrichtung.
Für containerisierte Anwendungen werden vorkonfektionierte Laufzeitumgebungen sowie native Kubernetes-Dienste angeboten. Bei Google sind Google das Kubernetes Engine (GKE) und Google Cloud Anthos. Es gibt auch Basis-Konfigurationen wie Pilot Light, bei der nur die kritischsten Anwendungen und Dienste berücksichtigt werden.
Mit Pilot Light können die mit der DR-Umgebung verbundenen Kosten für den regulären täglichen Betrieb drastisch gesenkt werden. Wenn ein Failover durchgeführt wird, kann der Rest der Infrastruktur bei Bedarf instanziiert werden.
Google Cloud Deployment Manager hilft dabei, Computer- und andere Cloud-Ressourcen aus einer vordefinierten Vorlage einfach und schnell neu zu erstellen.
Netzwerk
Bei einem Failover muss der Datenverkehr schnell vom primären zum sekundären Standort fließen. Client-Hosts und -Anwendungen sollten automatisch die aktive Site mit den Diensten finden, auf die sie zugreifen müssen. Dies wird normalerweise über den Domain Name Service (DNS) geregelt. In der Regel geschieht das automatisiert. Mit Google Cloud DNS können Failover-Dienste für eine DR-Site auch manuell erstellt werden. Google Cloud Traffic Director ermöglicht ein automatisches Failover.
Storage
Google bietet eine Vielzahl von Datenspeicherlösungen:
- verwaltete Dateidienste,
- iSCSI-Geräte auf Blockebene oder
- kostengünstige Objektspeicher.
Einige dieser Dienste bieten Redundanz innerhalb einer einzelnen Zone (Google Persistent Disks) oder über mehrere Zonen (Google Filestore, Google Cloud Storage). Zu beachten ist, dass jede am primären Standort verwendete Lösung berücksichtigt werden muss.
Beispiel: Bei Cloud-Compute-Engine-Instanzen, die Cloud Persistent Disks verwenden, werden die Daten am primären Standort gespeichert. Hier können Cloud Persistent Disks-Snapshots verwendet werden, um die Daten auch am DR-Standort vorzuhalten.
Die Rolle von NetApps Cloud Volumes ONTAP
Die Failover- und Failback-Prozesse in solch komplexen Umgebungen manuell zu entwickeln und zu testen ist schwierig, riskant und kostspielig. Cloud Volumes ONTAP ist die NetApp-Lösung für die Verwaltung von Unternehmensdaten in Google Cloud. Cloud Volumes ONTAP baut auf nativen Cloud-CPU- und Speicherressourcen auf. Die Lösung vereint eine Vielzahl von Datenspeicherdiensten auf einer einzigen Plattform, u. a.:
- NFS
- SMB / CIFS mit Active Directory-Integration
- iSCSI.
Die unterschiedlichen Daten und Formate werden mithilfe der NetApp-Replikationstechnologie – SnapMirror® – effizient zwischen lokalen NetApp ONTAP-Systemen und der Google Cloud repliziert. SnapMirror® bietet Datenreplikation auch transparent (ohne Änderungen am Clientsystem) auf Blockebene.
Inkrementelle Aktualisierungen schonen Bandbreite und Speicherplatzbedarf. Datenkomprimierung, Thin Provisioning und Deduplizierung reduzieren Platz und Kosten um bis zu 70%.
Integriertes Data Tiering verschiebt Daten je nach Bedarf automatisch und nahtlos zwischen Leistungs- und Kapazitätsstufen. Eine Kapazitätsstufe verwendet dabei für inaktive Daten den kostengünstigen Objektspeicher in Google Cloud Storage.
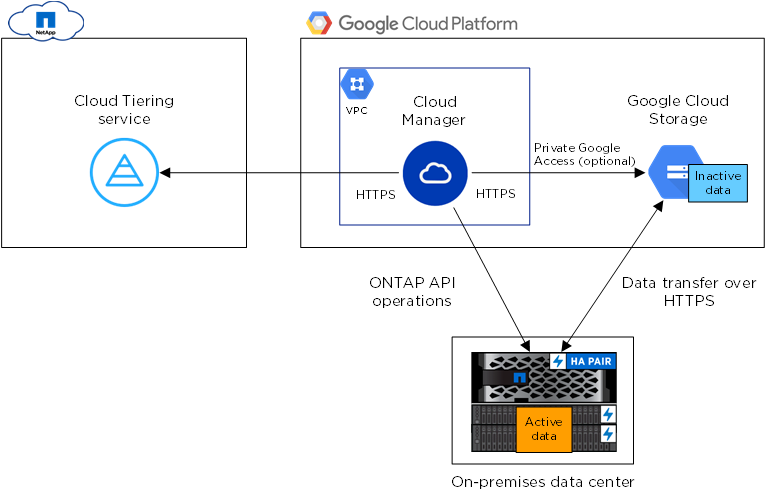
Nahtloses Failover und Failback
Der Cloud Manager ist eine benutzerfreundliche grafische Benutzeroberfläche und erleichtert die Durchführung der Failover- und Failback-Vorgänge, einschließlich der Konfiguration der SnapMirror-Replikation und Erstellen von FlexClone®-Volumes. Mit der NetApp FlexClone®-Funktionalität lassen sich schnell beschreibbare Klone z. B. für Testsuiten erstellen. Diese Klone können u. a. für eine bessere Auslastung der Ressourcen am DR-Standort verwendet werden. Über die RESTful API lassen sich die Aufgaben automatisiert oder als Teil eines umfassenderen Disaster-Recovery-Orchestrierungsplans ausführen.
Fazit: Cloud-Hosting spart die hohen Vorhaltekosten gegenüber herkömmlichen on-premises DR-Ansätzen und hilft, Ausfallzeiten drastisch zu reduzieren. Kombiniert mit einer intelligenten Datenmanagementplattform können jederzeit schützenswerte Daten zwischen Cloud und eigenem Rechenzentrum sicher übertragen werden. Lösungen wie NetApps Cloud Volumes ONTAP unterstützen Unternehmen jeder Größe bei der Automatisierung der DR-Prozesse.
Feature: Video-Interview mit Peter Wüst, Cloud Ambassador bei NetApp
