

Sven Breuner ist Field CTO International bei VAST Data. Für uns wagte er eine Prognose, wie es 2024 weitergehen könnte mit KI, GPTs, Deep Learning & Co. In seinem Gastbeitrag liefert er zudem neue Geschäftsideen für Service Provider.
KI und Storage im Jahr 2024
An künstlicher Intelligenz wird seit Jahrzehnten geforscht. Den jüngsten großen Durchbruch brachten die erstmals für den Massenmarkt verfügbaren GPTs (Generative Pre-trained Transformers) als eine Form der generativen KI. GPTs sind eine Art des maschinellen Lernens auf der Grundlage großer Sprachmodelle (Large Language Models, LLMs), welche Antworten, Ergebnisse und Erkenntnisse liefern, wie es auch ein Mensch tun würde.
2023 waren ChatGPT, Bard und andere LLM-Anwendungen überaus präsent in den Medien. Dieser erste Hype wird sich 2024 etwas beruhigen, während immer mehr neue Anwendungsfälle das Thema in die Breite bringen. Der Hype weicht auch der Realität, dass die Umsetzung ambitionierter Initiativen, um zum KI-gesteuerten Unternehmen zu avancieren, rar gesäte Fachkräfte erfordert und in der Komplexität nicht zu unterschätzen ist. Dennoch wird der KI-Boom anhalten, denn er verspricht großes Potenzial im neuen Jahr.
IDC hat die Ergebnisse einer Studie im Auftrag von Microsoft in Form einer Infografik veröffentlicht. The Business
Opportunity of AI gibt Einblicke in den geschäftlichen Nutzen von KI. Die Automatisierung von IT-Aufgaben, Cybersicherheit sowie von Geschäftsprozessen und Workflows sind aktuell die wichtigsten Anwendungsfälle, für die Unternehmen derzeit KI nutzen oder in den nächsten 24 Monaten zu nutzen planen. Für jeden US-Dollar, den Unternehmen in KI investieren, erhalten sie durchschnittlich dreieinhalb US-Dollar zurück. Fünf Prozent der Unternehmen weltweit erhalten im Durchschnitt sogar acht US-Dollar zurück. Unternehmen erzielen eine Rendite auf ihre KI-Investitionen innerhalb von 14 Monaten nach der Implementierung.
KI aus der Cloud liegt voll im Trend
GPUs und die Datenplattformen sind für den Erfolg von Deep Learning entscheidend. Chip-Mangel und enorme Preissteigerungen könnten den KI-Boom bremsen. Es muss dennoch keine KI-Bremse sein. Das KI-Fortschrittszentrum Lernende Systeme und Kognitive Robotik der Fraunhofer-Gesellschaft sieht eine Lösung darin, Methoden und Werkzeuge für KI-Projekte und KI-Entwickler-Workflows automatisiert in der Cloud zu nutzen. Damit entfällt einerseits die Anschaffung teurer Hardware und anderseits wird eine KI-Plattform einer breiteren Anwendergruppe zugänglich. In der Fraunhofer-Studie sind cloudbasierte KI-Plattformen definiert als Machine-Learning-as-a-Service (MLaaS)-Lösungen, die Datenspeicher, Rechenkapazität, Algorithmen, Schnittstellen etc. über die Cloud bereitstellen. Unternehmen, die auf diese Dienste zurückgreifen, müssen weder lokal Software installieren noch Server oder Storage-Ressourcen betreiben.
So gibt es bereits neben cloudbasierten KI-Plattformen der großen Anbieter wie Amazon, Google, IBM und Microsoft auch zunehmend kleine, spezialisierte KI-Cloud-Serviceprovider wie CoreWeave, Lambda Labs oder Core42. Diese setzen auf eine auf der DASE-Architektur (Disaggregated Shared-Everything) basierende Datenplattform, die in jeder Größenordnung vollparallel ist und die für KI-Supercomputer erforderlichen Optimierungen wie RDMA I/O und GPUDirect Services bietet.

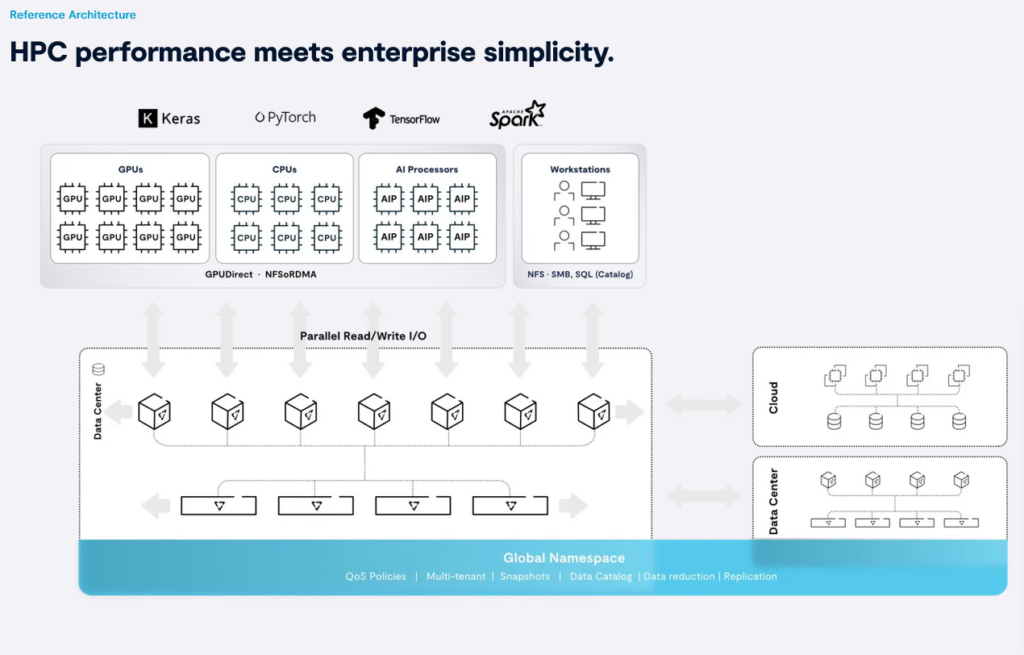
CoreWeave ist ein spezialisierter Cloud-Anbieter, der auf einer Hochleistungsinfrastruktur GPU-beschleunigte Rechenressourcen in großem Umfang flexibel nach Bedarf bereitstellt. Die On-Demand-GPU-Cloud von Lambda bietet GPU-Setups für LLM-Aufgaben. Core42 betreibt eine zentrale Datenplattform für ein globales Netzwerk von KI-Supercomputern, um Hunderte von Petabyte an Daten zu speichern und daraus zu lernen. Cloud-Serviceprovider in diesem neuen Marktsegment werden es immer mehr Unternehmen im Jahr 2024 ermöglichen, KI-Architekturen zu vertretbaren Kosten schnell aufzubauen, um von Deep Learning und LLMs zu profitieren.
Energieeffizienz rückt immer mehr in den Fokus
Mit zunehmender Verbreitung bekommt der Energieverbrauch der rechen- und speicherintensiven KI-Umgebungen immer mehr Aufmerksamkeit.
Werkzeuge der KI verbrauchen viel Strom, und die Tendenz ist steigend
Ralf Herbrich, Geschäftsführer des Hasso-Plattner-Instituts (HPI) in Potsdam und Leiter des Fachgebiets Künstliche Intelligenz und Nachhaltigkeit (Quelle: dpa)
Für einen Beitrag der Tageschau sprach Ralf Herbrich, GF des Hasso-Plattner-Instituts (HPI) und Leiter des Fachgebiets Künstliche Intelligenz und Nachhaltigkeit über den stark steigenden Stromverbrauch durch KI. Auf Rechenzentren sollen derzeit bereits bis zu fünf Prozent des weltweiten Energieverbrauchs entfallen. Es gibt Schätzungen, dass dieser Verbrauch durch die Nutzung digitaler Technologien, insbesondere KI, in den nächsten Jahren auf 30% ansteigen könnte. Auf jeden Fall wird der KI-Boom den Energiebedarf in die Höhe treiben.
Es ist 2024 an der Zeit, die Technologie im Rechenzentrum auf den Prüfstand zu stellen hinsichtlich Energieeffizienz und Nachhaltigkeit. Dies betriff vor allem die Speichertechnologie, die bei datenintensiven KI- und Deep-Learning-Workloads besonders gefragt ist. Als besonders effizientes Speichermedium gegenüber älteren Technologien konnte sich Flash in den letzten Jahren mit drei entscheidenden, erstmals kommerziell nutzbaren Innovationen hervortun.
Drei entscheidende Innovationen für noch effizienteres Flash
Neben Energie- ist auch Kosteneffizienz gefragt. Beides geht oft Hand in Hand. Hyperscale-Flash-SSDs mit hoher Speicherdichte stellen Kapazität für Storage-Anwendungen direkt bereit – ohne Überprovisionierung, Pufferspeicher oder Dual-Port-Schnittstellen wie bei herkömmlichen Enterprise-SSDs. Neue, an die interne Geometrie von Hyperscale-SSDs anpassbare Datenstrukturen minimieren die Abnutzung der Isolierschicht der immer dichteren Flash-Zellen bei Löschvorgängen.
Storage Class Memory (SCM) als besonders ausfallsicherer Hochleistungsspeicher weist eine längere Lebensdauer gegenüber NAND-Flash auf. SCM ist ein Flash-Speicher ähnlich dem klassischen DRAM mit geringer Latenz und hoher Übertragungsgeschwindigkeit. Im Gegensatz zu DRAM ist SCM-Speicher jedoch nicht flüchtig, verliert somit keine Daten, wenn die Stromversorgung unterbrochen wird. SCM absorbiert Schreibvorgänge, um den Flash-Verschleiß zu minimieren.
Storage-Software in Stateless-Containern ist so konzipiert, dass sie im laufenden Betrieb aufrüstbar ist. Diese zustandslosen Maschinen beherbergen die Logik des gesamten Clusters und sind für alle I/O-, Datenbank- und Speicher-Controller-Funktionen verantwortlich. Diese Cache-freie Architektur bedeutet, keine Daten zwischenspeichern zu müssen. Mit Stateless-Containern war es erstmals möglich, sehr leistungsfähige Arrays für Scale-out File and Object Storage zu realisieren.
Datenqualität wird immer wichtiger
2024 wird die Datenqualität immer wichtiger. Datenhygiene und Datenkuratierung unfassen sämtliche Prozesse u. a. der Datenerfassung und -aufbereitung, um die Reinheit der Daten zu gewährleisten. Für die besten KI-Ergebnisse müssen Daten genau, aktuell und konsistent sein. Ein weiteres Trendthema ist Data Observability. Laut Definition von Gartner bezeichnet das die Fähigkeit, zu verstehen, was innerhalb eines Systems vor sich geht. Die Beobachtbarkeit von Daten setzt voraus, dass verwertbare Daten aus verschiedenen Quellen in geeigneter Weise miteinander verbunden, optimiert und kontextbezogen erweitert werden. Ziel ist es, Unternehmen in Zukunft schnellere und genauere Entscheidungen zu ermöglichen.
Alle das soll dazu beitragen, dass die Investitionen in KI, GPTs, Deep Learning & Co. im neuen Jahr auch Früchte tragen.


Sven Breuner ist Field CTO International bei VAST Data. Seine Karriere startete er 2005 im Fraunhofer Competence Center for High Performance Computing. Seine Kenntnisse in den Bereichen Speichersysteme, Linux-Kernel-Entwicklung und schnelle Interconnects bildeten die Grundlage für die Entwicklung der Architektur eines parallelen Dateisystems für Fraunhofer (BeeGFS). Er leitete mehrere Jahre lang das Fraunhofer BeeGFS-Entwicklungsteam und kümmerte sich um die Einführung des Systems in HPC-Zentren rund um den Globus. Im Jahr 2008 machte er seinen Master in Informatik mit einer Arbeit über effizientes verteiltes Metadatenmanagement in parallelen Dateisystemen. Er gehörte 2014 zum Gründerteam von ThinkParQ, einem Fraunhofer-Spin-off-Unternehmen mit Fokus auf die Weiterentwicklung von BeeGFS und professionelle Dienstleistungen. Als CEO von ThinkParQ leitete er das Unternehmen bis 2019. Anschließend begleitete er die die Einführung von Excelero in Rechenzentren rund um den Globus. 2021 wechselte der Experte für leistungskritische verteilte Systeme zu VAST Data.



