

Kubernetes ist ein Werkzeug zur Orchestrierung containerbasierter Anwendungen. Eigentlich. Es soll u. a. die Bereitstellung von Containern, die Verteilung von Workloads und die Verwaltung der Ressourcen automatisieren. Entwickelt hat es Google für seine eigene Cloud-Plattform. Kubernetes (K8s) war von Anfang Open Source. Mit Gründung der Cloud Native Computing Foundation (CNCF) übergab Google das Projekt an die Linux Foundation. Mittlerweile bildet das K8s-Universum eine der größten Open-Source-Communities. Es gibt unzählige Erweiterungen und Lösungen, die auf K8s aufsetzen. Alle großen Hyperscaler und viele kleinere Cloud Service Provider (CSP) unterstützen K8s. Allerdings: einfach ist es nicht.
Unternehmen schätzen die Vorteile gegenüber klassischer Virtualisierung und nutzen Container immer öfter auch für Stateful-Anwendungen in Produktivsystemen. Container sind schlanker und haben weniger Overhead als eine virtuelle Maschine (VM), stehen schneller bereit und sind insgesamt agiler. Containerisierte Anwendungen und Workloads sind unabhängig von der darunter liegenden Infrastruktur und lassen sich über standardisierte Schnittstellen oder mit Hilfe von Skripten problemlos zwischen unterschiedlichen Plattformen oder Providern bewegen.
Virtualisierung vs. Container
Zunächst einmal basieren beide auf physischer Hardware. Während es bei einer Virtualisierung auch ein einzelner Server sein kann, sind es bei Containern immer Server-Cluster. Damit eine VM oder ein Container etwas mit der Hardware anfangen kann, braucht es einen Virtualisierungslayer. Für die Container ist das ein Cloudbetriebssystem (Cloud-OS) wie z. B. OpenStack oder ein Datacenter-Betriebssystem (DC/OS) wie Mesosphere. Bei den VMs kommen Hypervisor wie z. B. VMware ESXi, Hyper-V, KVM oder Proxmox zum Einsatz.
Ab hier beginnen die Unterschiede. Ein Hypervisor unterteilt einen physischen Server in mehrere virtuelle Maschinen. Wie jeder klassische Server benötigt auch eine VM erst einmal ein Betriebssystem, damit Anwendungen installiert werden können. Der Hypervisor verwaltet die Hardware-Ressourcen und sorgt dafür, dass eine VM die benötigte Rechenpower und ausreichend Storage zur Verfügung hat.

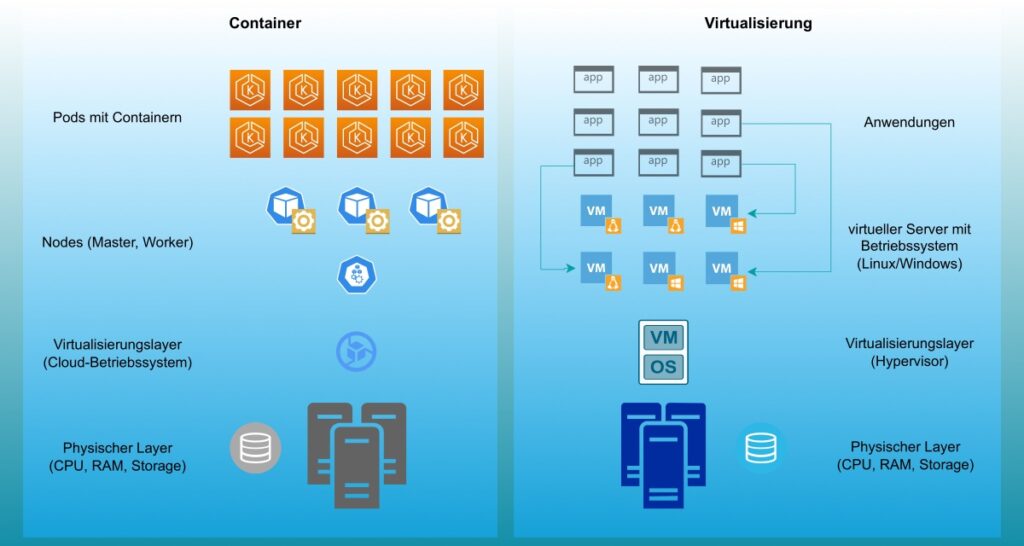
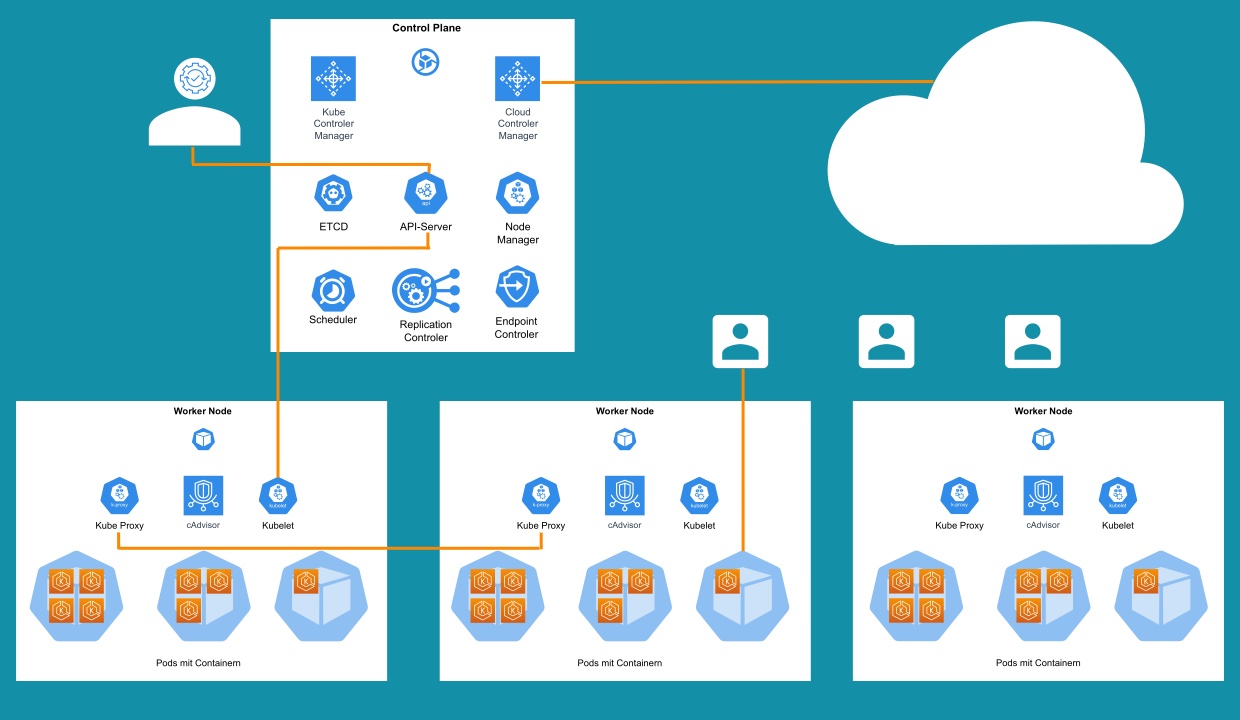
Ein Cloud-OS besteht aus einzelnen Komponenten. Aus Sicht der Hardware ist das Cloud-OS ein Hypervisor. Aus Sicht von Kubernetes ist es eine VM. Kubernetes selbst wiederum besteht ebenfalls aus mehreren Komponenten. Die Container werden in Pods organisiert. Ein Pod kann nur einen oder mehrere Container beherbergen. Pods laufen auf so genannten Worker-Nodes. Für die Orchestrierung braucht es dann noch eine Master Node (auch Control Plane).
Jeder Worker- und Masternode besteht wiederum aus diversen Komponenten.
Im Master Node bildet ein ein Kube API-Server die Kontrollebene und führt administrative Aufgaben aus. Außerdem ist der API-Server das Frontend für Benutzer, um Befehle entgegenzunehmen. Das können YAML- oder JSON-Skripte sein. Mit ETCD stellt Kubernetes seinen eigenen Key-Value-Store zur Verfügung. Dort finden sich u. a. Informationen zu Clusterstati oder Konfigurationen. Der Kube-Scheduler verwaltet Anfragen vom API-Server und verteilt die Workloads auf die einzelnen Nodes. Ein Cloud-Controller-Manager verbindet Cluster mit der API eines Cloud-Anbieters und sorgt für etwas Sicherheit, indem er die Komponenten, die mit dieser Cloud-Plattform interagieren, von den Komponenten trennt, die nur mit dem Cluster interagieren. Der Kube Controler Manager vergleicht den aktuellen Status von Objekten in Kubernetes mit der Vorgabe des API-Servers. Gibt es Abweichungen, werden korrigierende Maßnahmen und weitere Kontrollschleifen umgesetzt. Dann gibt es noch den Node Manager, der die einzelnen Nodes verwaltet. Er kann bei Nichtverfügbarkeit einer Node auch neue Knoten erstellen. Und schließlich gehören noch ein Replikations- und ein Endpunkt-Controller dazu. Die machen genau das, was der Name sagt: Der Replication Controller verwaltet die Container in Replikationen. Der Endpoint Controller verbindet Container mit Pods.
Die Worker Nodes wiederum beherbergen zunächst einen Agenten, Kubelet, der für die Kommunikation mit der Control Plane zuständig ist. Das Kubelet sorgt auch dafür, dass Anweisungen vom Master ausgeführt werden, wie z. B. einen neuen Container bereitzustellen oder einen nicht mehr benötigten zu zerstören. Außerdem überwacht ein integrierter Agent (cAdvisor) Ressourcennutzung sowie Health-Status der Container und analysiert die Leistung von Containern. Der Kube Proxy verwaltet Netzwerk-Policies und stellt sicher, dass die Regeln auch richtig definiert sind. Er ist die Schnittstelle, über die alle Worker Nodes und Container miteinanander kommunizieren können. Die Container Runtime ist für das Ausführen der Container verantwortlich. Und natürlich gibt es noch die Pods. Pods nutzen eine gemeinsames Speicher/Netzwerk und Spezifikation für die Ausführung der Container. Innerhalb eines Pods können Container genauso miteinander reden, als wären sie auf demselben Rechner.

Cloud-native oder Container-native
Cloud-native Anwendungen sind für den Containerbetrieb optimiert und werden speziell für den Einsatz in Cloud-Computing-Plattformen entwickelt. Anders als beim klassischen, monolithischen Ansatz, wird eine cloud-native Applikation in einzelne Funktionen (Microservices) aufgeteilt. Jeder dieser Microservices läuft in einem eigenen Container. Damit werden Anwendungen extrem skalierbar und sie können sogar standortübergreifend betrieben werden. Dieser Ansatz macht Applikationen resistenter und man muss nicht immer den kompletten Softwarecode anfassen, wenn mal eine Funktion nicht tut was sie soll oder aktualisiert werden muß. Mit containernative geht die Entwicklung noch einen Schritt weiter. Dort sind Entwicklungs-, Test- und Bereitstellungs-Plattform identisch, nämlich ein Docker-Container (Dockerization of an Application). Containernative Anwendungen sind i. d. R. serverless – im Prinzip ein extrem hoher Infrastruktur-Abstraktionslayer.
Allerdings hat diese große Unabhängigkeit und Agilität einen Preis: Verwaltung und Administration können beliebig komplex werden. Ein hoher Aktualisierungsgrad und die immense Dichte von Containern haben erhebliche Auswirkungen auf die Infrastrukturkontrolle. Im Vergleich zu einer VM lassen sich mit Containern bis zu zehnmal so viele Serverinstanzen auf der gleichen Hardware betreiben und damit auch entsprechend mehr Anwendungen.
Zwar lassen sich übersichtliche oder einfache Containerlandschaften noch mit Automatisierungstools wie Ansible, Salt und Chef oder simplen Orchestrierungslösungen wie Docker Swarm verwalten – alle bieten die Bereitstellung, Überwachung und Verwaltung von Containern. Jedoch kommen alle diese Lösungen schnell an Grenzen. Hier kommt Kubernetes ins Spiel, dass darüber hinaus ein hohes Maß an Interoperabilität, eine Selbstheilungsfunktion und die Orchestrierung von Storage bietet. Zudem können mit K8s Rollouts und Rollbacks automatisiert werden. Container, die eine Anwendung bilden, werden in logischen Einheiten gruppiert. Das vereinfacht Verwaltung und Monitoring.
Klingt einfach? Ist es aber nicht. Ein Blick ins K8s-Handbuch ist eher ernüchternd – im Ruhrpott würde man die Anleitung liebevoll mit „von Höcksken auf Stöksken“ beschreiben.
Und dann gibt es noch das:
Problemkind Storage
Traditionelle Storageprodukte und -architekturen können die Anforderungen von containerisierten Anwendungen und Workloads nicht erfüllen. Herkömmliche Storagelösungen sind nicht Anwendungs-aware. Kubernetes indes hat keine Storage-Awareness. Selbst Cloud-Storage eignet sich nur bedingt und benötigt eine zusätzliche Ebene, um Dinge wie Hochverfügbarkeit, Portabilität und Backup bzw. Disaster Recovery auf Container-Ebene abzubilden.
Was immer wieder gern vergessen wird: Bei containerisierten Anwendungen reicht ein einfaches Backup von Daten nicht aus. Bei einem containernative Backup müssen immer auch die Metadaten, die Anwendung und die Kubernetes-Konstrukte (Pods, Datenträger, Konfiguration) mit gesichert werden. Die sind oft auf ein Server-Cluster verteilt. Für eine schnelle und zuverlässige Wiederherstellung müssen alle diese Komponenten gemeinsam gesichert werden. Auch sollten sowohl zustandsbehaftete (stateful) und zustandslose (stateless) Anwendungen unterstützt werden.
Containernative Storage sollte zudem in der Lage sein, komplexe QoS- und Service-Level-Management-Abhängigkeiten zu verwalten und Bare-Metal-Leistung für Block-, Datei- und Objektspeicher abzubilden. Viele Cloud-Storagelösungen unterstützen entweder nur Block-, nur Object- oder nur File-Storage bzw. scheitern an der Portabilität, an der Automatisierung von Day-2-Operationen (Backup, DR) und dem Lifecycle-Management von Backups und Snapshots (Pruning).
Von der Insellösung zur Distributed Stateful Edge Platform
Mittlerweile haben selbst Hyperscaler wie Googe erkannt, dass K8s schwer zu bändigen ist. Mit Autopilot stellt Google eine Automatisierungfunktion für geplagte ITOM-Teams bereit. Der Nachteil? Autopilot ist weniger flexibel als K8s, erlaubt keinen Shell-Zugriff mehr, unterstützt nur noch knapp ein Drittel der möglichen Anzahl von Containern in einem Pod und: Es steht Admins ausschließlich auf der Google-eigenen Kubernetes Engine (GKE) zur Verfügung.
Andere Plattformen, wie Portworx von Pure Storage, Piraeus von LINBIT oder oder Rook verwalten ausschließlich Storage für Kubernetes und wieder andere, wie Pulumi, kümmern sich nur um Infrastruktur. Viele sind ausschließlich auf CEPH beschränkt. Marathon ist speziell für das DC/OS Mesosphere optimiert. Das sind nur einige Beispiele in einem Meer kleinerer und größerer Insellösungen.
If you build a product, you have to build it for real use cases.
Partha Seetala, President Cloud BU bei Rakuten Symphony
Der echte Use Case heute sind Unternehmen, die ihre komplette Infrastruktur über zum Teil mehrere 10.000 Lokationen verteilen. Dazu nutzen viele Cloud-Technologie wie Kubernetes. Schon heute verteilen Firmen ihre Workloads über verschiedene Clouds und diverse SaaS-Anbieter sowie unzählige eigene Assets auf der ganzen Welt (Stichwort Edge). Silos können sich solche Unternehmen nicht leisten. Sie müssen an jedem Standort von der Zentrale über öffentliche Cloud Plattformen bis hin zum entferntesten Edge den Überblick und die Kontrolle behalten. Sie wollen standort- und herstellerübergreifend skalieren, Anwendungen bereitstellen und verwalten, den Zustand kontrollieren und nach Möglichkeit auch etwas für die Umwelt tun und Energieverbrauch (und -kosten) senken – und das bevorzugt in einer übersichtlichen, einheitlichen Plattform.
Eine neue Herausforderung kommt zudem mit dem Edge: Wenn Daten nicht dort verarbeitet werden, wo sie entstehen, fallen hohe Übertragungskosten an von Standorten, die netzwerktechnisch oft gerade noch so eine Bandbreite von 2G erreichen. Schlechte End-to-End-Leistungen führen zu schlechten Nutzererfahrungen. 5G soll helfen und vor allem das Edge mobilisieren. 5G ist aber eine reine Cloud-Anwendung (mit ein bisschen notwendiger Hardware unten drunter). Immer mehr Unternehmen bauen sich private 5G-Netze. Für ohnehin oft schon überlastete ITOM-Teams bedeutet das noch mehr Komplexität und noch mehr Arbeit. Wie schön wäre jetzt eine Eier legende Wollmilchsau.
Et voilà: Symworld Cloud ist eine anwendungsorientierte Management-Plattform für datenintensive Anwendungen und Workloads in (O)RANs, am Edge oder Core. Mit der Plattform lässt sich zudem die Verwaltung von Baremetal-Servern, Storage sowie Netzwerkkomponenten und -diensten automatisieren.
Unterstützt Stateful-, 5G- und Edge-Anwendungen, Storage und Netzwerk für K8s – at scale

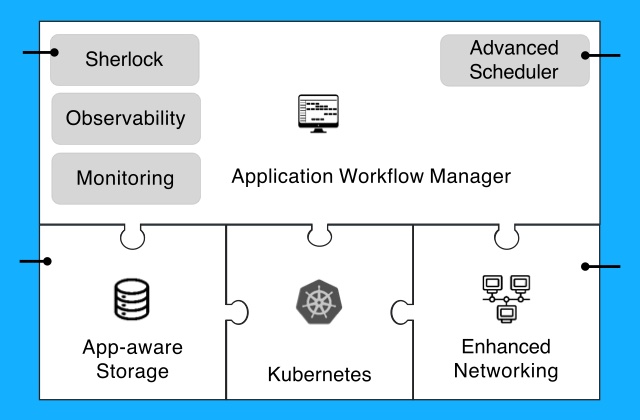
Symworld Cloud besteht aus drei einzelnen Produkten:
- Symworld Cloud Native Plattform (CNP) ist eine vollständig integrierte, erweiterte Kubernetes-Plattform, optimiert für die Ausführung von speicher- und netzwerkintensiven Diensten mit besonderem Schwerpunkt auf Zero-Touch-Bereitstellung und Betriebsautomatisierung am Edge
- Symworld Cloud Native Storage (CNS) ist ein leistungsstarker Cloud-nativer Storage-Stack für Kubernetes mit besonderem Fokus auf Storage- und anwendungsorientiertem Datenmanagement, bei dem Volumes und Applikationen als eine einzige logische Gruppe verarbeitet werden können.
- Symworld Orchestrator ist ein hochgradig skalierbarer Infrastruktur- und Service- bzw. Anwendungs-Orchestrator zur Verwaltung von Baremetal-Servern und Applikationen über Server, Cluster und Rechenzentren hinweg.
The Network is a complex beast.
Partha Seetala versteht den Networking-Stack
Symworld Cloud ist optimiert für die Bereitstellung von 4G/5G RAN, ORAN, Core und NFV im großen Maßstab. 4G- und 5G-RAN (DU, CU-CP und CU-DP) können auf COTS-Hardware in wenigen Minuten ausgerollt werden. Die Möglichkeit der zentralisierten Orchestrierung von Zehntausenden von Zellstandorten und Basisbandeinheiten stand von Anfang an bei der Entwicklung der Plattform im Fokus.
Das erweiterte Networking unterstützt mehrere, persistente Internetprotokolle, mehrere Netzwerkkarten, Over- und Underlays (Calico, OVS, VLAN, SR-IOV, DPDK), Dual-Stack IPv4/IPv6 und Netzwerkrichtlinien.


Die Workload-Orchestrierung der Plattform arbeitet auf Basis von Policies – dynamisch und automatisch. Anwendungen können Leistung von spezifischen GPUs anfordern. CPU-Cores werden dediziert Workloads zugewiesen.
Symworld Cloud sitzt im Userspace zwischen Betriebssystem und K8s. Die Plattform kann auf Baremetal oder in Containern sowie VMs, on premises oder in der Cloud betrieben werden.
Wenn Du eine Plattform baust, musst du auch einen Storage Stack haben.
Partha Seetala war Gründer und CEO von Robin.io
Mit Symworld CNS lässt sich verfügbarer Speicher, der an Worker Nodes angeschlossen ist, aggregieren. Dabei ist es egal, ob es sich um File-, Object- oder Blockspeicher handelt und welches Medium darunter liegt. So wird eine einheitliche persistente Speicherebene für containerisierte Datenbanken oder andere zustandsabhängige Anwendungen geschaffen.

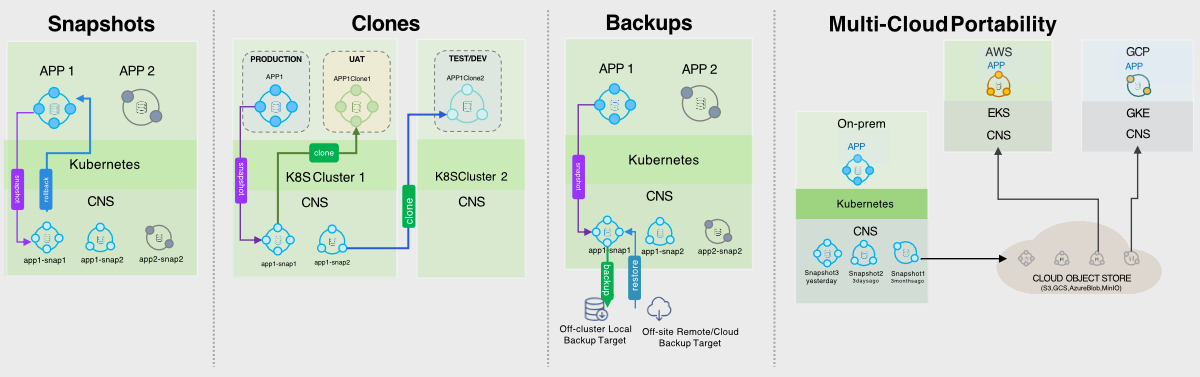
Symworld CNS bietet darüber hinaus zusätzliche Funktionen wie Volume-Snapshots, Volume-Verschlüsselung, Klone, integriertes Backup sowie Disaster Recovery und ist Multi-Cloud-fähig.
Die Preise basieren auf Maschinen (nicht Containern oder Pods!) sowie beim Storage auf Kapazität. Der Orchestrator kostet extra.
Der komplette Stack von Symworld Cloud ist eine Eigenentwicklung. Dazu sollte man wissen, dass Rakuten Symphony im April 2022 den Kubernetes-Storage-Experten robin.io vollständig übernommen hat. Rakuten-CEO Tareq Amin ist stolz darauf, dass „die Cloud-Umgebung für die zentrale Einheit (CU), die verteilte Einheit (DU), der IMS-Kern (Internet Protocol Multimedia Subsystem), der Paketkern – alles und jedes – auf Robin.io“ läuft.
In Deutschland zählt 1&1 zu den Flagschiffkunden. Der Anbieter hat einen 10-Jahresvertrag mit Rakuten abgeschlossen. 1&1 ist Teil von United Internet und plant aktuell das vierte Mobilfunknetz in Deutschland. Rakuten hat im Rennen um den Vertrag Schwergewichte wie Cisco, Mavenir oder NEC auf die Plätze verwiesen.
Mit Rakuten haben wir den weltweit einzigen Open RAN-Experten an unserer Seite, der wirklich über umfangreiche praktische Erfahrungen mit dieser neuen Technologie verfügt. Rakuten ergänzt unser Know-how bei Telekommunikationsnetzen, Rechenzentren und Cloud-Anwendungen optimal. Gemeinsam werden wir ein hochleistungsfähiges Mobilfunknetz aufbauen, das über eine umfassende Automatisierung und Agilität verfügt, um das Potenzial von 5G voll auszuschöpfen. Durch die vollständige Virtualisierung und den Einsatz von Standardhardware können wir die besten Produkte flexibel kombinieren. So werden wir zu einem herstellerunabhängigen Innovationstreiber im deutschen und europäischen Mobilfunkmarkt.
1&1 CEO Ralph Dommermuth
Versuche von 1&1 mit drahtlosen Festnetzzugangsdiensten (Fixed Wireless Access, FWA) lieferten Geschwindigkeiten von 1 Gbit/s und Datenübertragungen von mehr als 8 Terabyte pro Klient über einen Zeitraum von 24 Stunden – bei einer Latenz von nur 3 Millisekunden.
Die erste Errungenschaft ist es, eine Latenzzeit von 3 Millisekunden zu liefern und einen Minecraft-Anwendungsserver, die UPF [User Plane Function], CU, DU und Robin.io alle im selben Pod unterzubringen. Das ist einfach genial.
Tareq Amin freut sich über den Durchbruch.
Wir trafen den Robin.io-Gründer und President der Cloud Business Unit bei Rakuten, Partha Seetala, im Rahmen der IT Press Tour im Januar 2023 in San Jose, Kalifornien.





