

Lösungen von IBM, NetApp, VMware oder Qumulo werden von vielen Organisationen eingesetzt. Nicht immer bieten die Plattformen aber alle benötigten Funktionen oder Schnittstellen. Natürlich könnten Anwender von IBM, NetApp oder Qumolo fehlende Schnittstellen und Integrationen bei den Herstellern individuell beauftragen. Rentabel ist das allerdings nur für wirklich große Umgebungen. Kleinere Firmen sind entweder nicht attraktiv genug bzw. stünde der finanzielle Aufwand in keinem Verhältnis zum späteren Nutzen. Hilfe kommt von externen Dienstleistern. Wir stellen euch in unserer Artikelserie Backup für Legacy-Storage Lösungen vor, die für euch die Herausforderungen bei der Arbeit mit den Großen erleichtern. Im zweiten Teil stellen wir euch mit Yuzuy ein Startup aus Deutschland vor.
Backup für Qumulo
Qumulo hat sich auf die Entwicklung von Dateisystemen und Speicherlösungen spezialisiert. Dafür verfolgt der Hersteller einige innovative Ideen. Kunden überzeugt vor allem die einfache Implementierung und Verwaltung. Ein API-first-Ansatz und die extrem hohe Skalierbarkeit sowohl in Bezug auf Größe als auch Leistung auch über Private- und Public Clouds hinweg machen die Lösung superflexibel. Die Scale-out-Architektur erlaubt es, Hardwareknoten hinzuzufügen, ohne dass es zu Unterbrechungen oder Fehlern bei einer Datenmigrationen kommt. Daten können nahtlos zwischen lokalen Speicherressourcen und der Cloud bewegt werden.
Qumulo verwendet ein verteiltes Dateisystem, das es mehreren Knoten in einem Cluster ermöglicht, gemeinsam auf denselben Speicher zuzugreifen. Mit der Fähigkeit zur Echtzeitanalyse erhalten Benutzer Einblicke in ihre Daten, in die Speicherbelegung und Zugriffsmuster. Integrierte Verschlüsselung, starke Authentifizierung und Zugriffskontrollen sorgen für ein hohes Maß an Sicherheit.
Das alles macht Qumulo zu einem interessanten Anbieter für Unternehmen, die mit großen Dateisystemen arbeiten und nach skalierbaren und leistungsstarken Speicherlösungen suchen. Die Herausforderungen beginnen mit dem Backup oder bei der Synchronisation.
Das Sichern großer Dateisysteme ist eine komplexe Aufgabe. Große Dateisysteme können Terabytes oder sogar Petabytes an Daten enthalten. Das Sichern einer so großen Datenmenge erfordert erhebliche Ressourcen und kann viel Zeit in Anspruch nehmen. Backup-Operationen sollten in einem begrenzten Zeitrahmen durchgeführt werden, um die Auswirkungen auf den laufenden Betrieb zu minimieren. Bei großen Dateisystemen kann es schwierig sein, das Zeitfenster einzuhalten. Das Übertragen großer Datenmengen über das Netzwerk kann die verfügbare Bandbreite belasten und die Leistung des Netzwerks für andere Aufgaben beeinträchtigen. Und große Dateisysteme erzeugen große Backup-Dateien, was zusätzlichen Speicherplatzbedarf mit sich bringt. Auch sind große Dateisysteme anfälliger für Datenkorruption oder Fehler, die sich auf die gesicherten Backups auswirken können.

Das Backup großer Dateisysteme erfordert daher den Einsatz von leistungsstarken Backup- und Wiederherstellungslösungen sowie eine sorgfältige Planung und Ressourcenallokation, um wichtige Daten zuverlässig zu sichern und im Falle eines Datenverlusts schnell wiederherstellen zu können. Backup-Lösungen müssen mit dem Dateisystemen skalieren, ohne an Effizienz und Zuverlässigkeit zu verlieren sowie optimierte Wiederherstellungsmethoden verwenden.
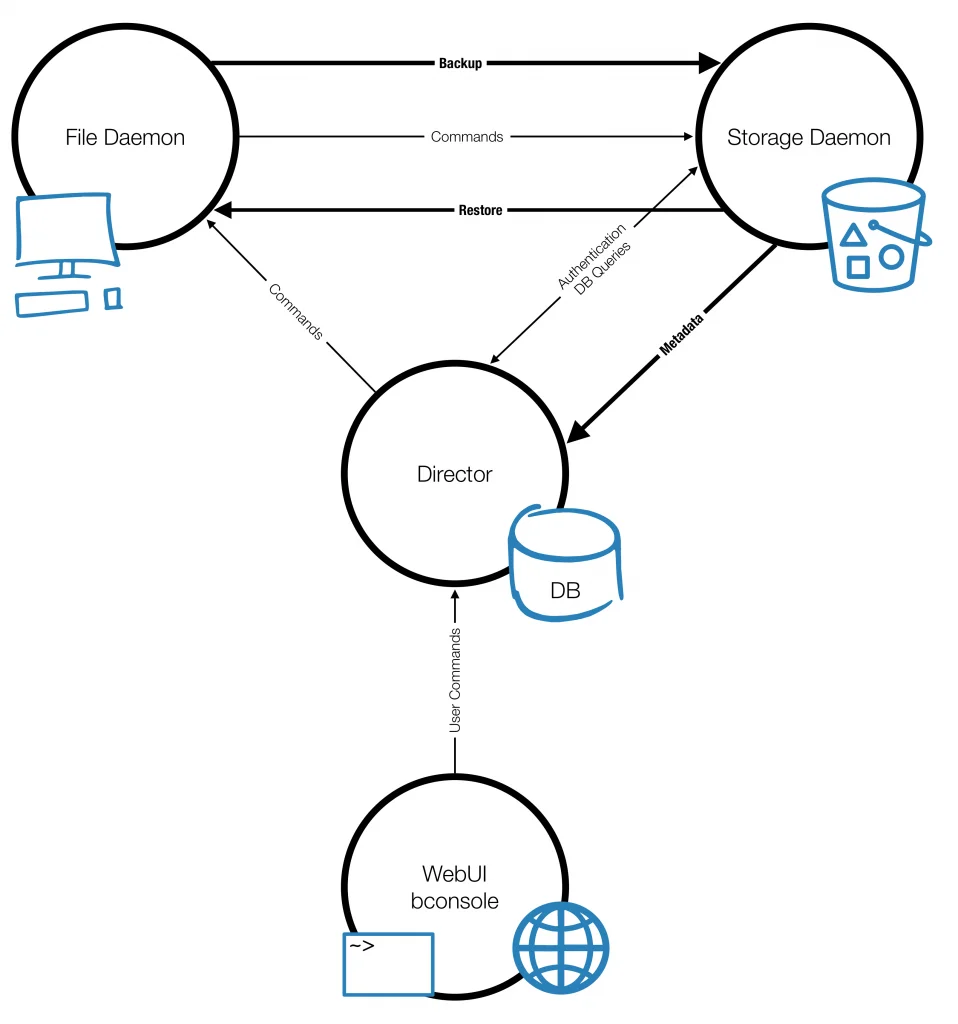
Eine Lösung, die viele dieser Anforderungen erfüllen kann, ist Bareos. Die Open-Source-Backup-Software wurde entwickelt wurde, um die Sicherung und Wiederherstellung von Daten in Unternehmensumgebungen zu erleichtern. Bareos steht für Backup Archiving Recovery Open Sourced und spiegelt die Grundprinzipien der Software wider.
Aber wir haben doch keine Zeit!
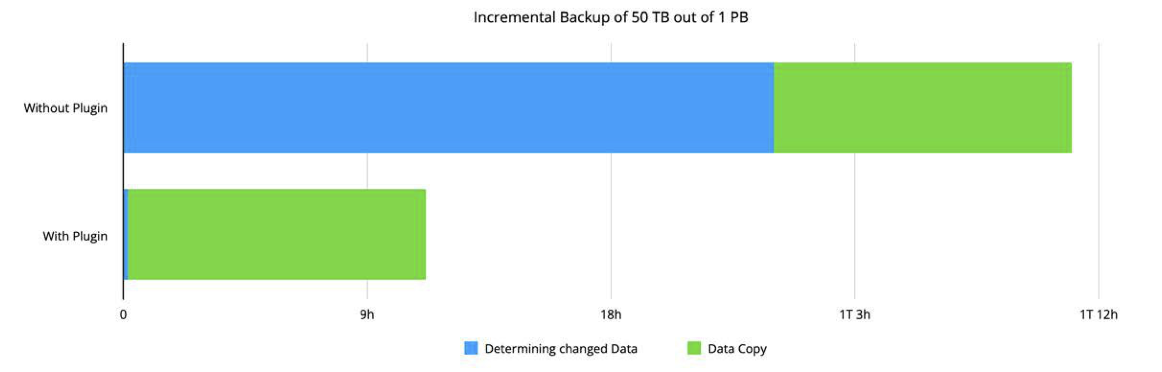
Die Sicherung von Daten aus Enterprise-NAS-Systemen erfordert Zeit. Viel Zeit! Das ist für viele Backuplösungen eine immense Herausforderung. Grund ist die Notwendigkeit, den gesamten Dateibaum Schritt für Schritt nach Änderungen durchsuchen zu müssen. Dieser Prozess kann in der Petabyte-Äre mehrere Tage oder sogar Wochen dauern.
Einfacher ginge es, die Änderungen mit Snapshots zu verfolgen. Yuzuy, ein Startup aus Hamburg, nutzt die Metadaten der in Qumulo integrierten Snapshots zur Ermittlung der Änderungen. Ein Plugin verbindet dazu die Qumulo File Data Platform über eine API mit der Backuplösung von Bareos. So lassen sich Änderungen schneller erfassen. Das Backupfenster für ein inkremetelles Backup von 50 TB aus einem 1-PB-großem Storage schrumpft von ca. 35 auf zehn Stunden.

Bareos verwendet Standardformate für Backups und Metadaten. Das erleichtert die Portabilität von Daten zwischen verschiedenen Backup-Systemen. Die modulare Architektur ermöglicht es Benutzern, nur die benötigten Komponenten zu installieren und zu konfigurieren. Die Unterstützung verschiedene Arten von Backups, einschließlich Vollbackups, inkrementeller Backups und differentieller Backups erlaubt die effiziente Nutzung von Speicherplatz und Bandbreite.

Kunden wissen vor allem die Wirtschaftlichkeit der Lösung zu schätzen. Für die Nutzung der Bareos-Software fallen keine Lizenzgebühren an. Wie bei vielen Open-Source-Lösungen zahlen Kunden auch bei Bareos nur für Updates, Support, Beratung und Schulung. Ein weiterer Vorteil: Der Hersteller ist ein deutsches Unternehmen.
Yuzuy kann aber noch mehr als nur das Backup großer Dateimengen zu beschleunigen, z. B. die
Ausfallsicherheit in Qumulo Clustern automatisieren
Eine virtuelle Appliance hilft Admins, Failover und Failback zu automatisieren – und ohne etwas zu zerstören, das noch intakt ist. Außerdem können die mit einer Replikationsbeziehung verbundenen Konfigurationen automatisch synchronisiert werden.
Normalerweise sind bei Qumulo eine Vielzahl von API-Calls, CLI-Befehlen oder Skripten für diese Vorgänge erforderlich. Die sind aber schwierig zu entwickeln, zu pflegen und nicht immer einfach im Handling. Meist fehlt auch Zeit für das Training neuer oder weniger erfahrender Mitarbeiter im Umgang mit der Konsole und den Skripten.
Der Einsatz von Skripten, komplizierte Failover- oder Fallback-Prozesse und viele Prüfungen erhöhen zudem die Komplexität. Je nach Client-Zugriffsprotokoll oder welcher Cluster ist betroffen ist, kann das zu unterschiedlichen Szenarien und jeder Menge möglicher Fehler führen. Auch gibt es auch immer wieder Aufgaben, die sich nicht oder nicht so einfach durch Skripting lösen lassen. Ganz abgesehen davon, dass manueller Aufwand in ohnehin schon überlasteten ITOM-Teams nicht selten zu Fehlern und Versäumnissen führt. Das Risiko für Sicherheitsvorfälle oder Systemausfälle steigt.
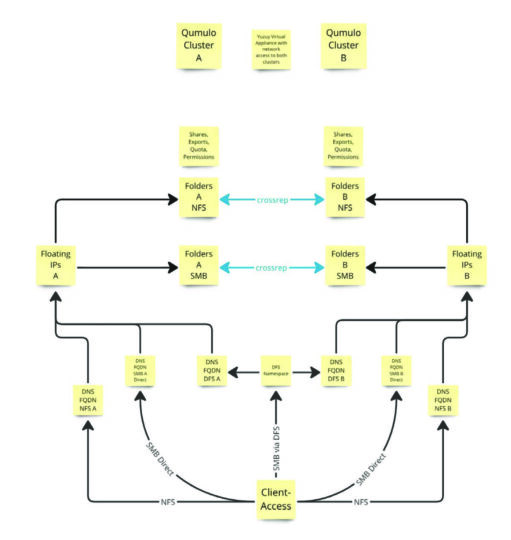
Yuzuy ermöglicht ein für die Clients transparentes Failover. Standardmäßig werden die Erstellung oder Änderung von NFS-Exporten, SMB-Freigaben, Quotas und Berechtigungen nicht automatisch repliziert. Die Yuzuy-Synchronisierung repliziert kontinuierlich und fast in Echtzeit alle NFS-Exporte, SMB-Freigaben und Quotas zwischen zwei Clustern – selbst zwischen cross-replicating Clusters. Auch im Failover-Modus katalogisiert Yuzuy alle Änderungen auf dem sekundären System und repliziert sie auf den primären Cluster, wenn dieser wieder verfügbar ist. Dabei erkennt die Lösung, ob eine Komponente Teil eines Replikationsszenarios ist und synchronisiert nur das, was auch repliziert werden soll.

Yuzuy ist als VMware-Image verfügbar und läuft auf einem lokalem Hypervisor oder in der Cloud. Mit dem Installationsassistenten ist die Appliance schnell aufgesetzt. APIs sorgen für Integrationen, z. B. in bestehende ITSM-Systeme.
Wir trafen Yuzuy-Gründer und CEO Martin Kohl sowie Bareos-VP Frank Kohler im Ramen der IT Press Tour im Juni 2023 in Berlin.





